Media.net is a leading advertising technology company that offers a wide range of solutions for publishers, advertisers, and agencies. 
With a focus on contextual advertising, Media.net has established itself as a key player in the digital advertising ecosystem.
It provides a platform that allows for the monetization of website content through highly relevant ads, thereby creating a win-win situation for both publishers and advertisers.
Why Scrape Data from Media.net?
Revenue Maximization
Scraping Media.net allows publishers and advertisers to understand the types of ads and pricing models available, aiding in the formulation of more effective marketing strategies and business plans for revenue maximization.
Competitive Intelligence
Media.net is a global leader in the ad-tech industry. Gathering data from this platform offers competitive intelligence that can be crucial for understanding market trends and shaping your business strategy.
Engagement Metrics
Media.net prioritizes user experience by offering customized native ads. Analyzing engagement metrics such as engagement rates from real users can help optimize your own user engagement strategies.
Technological Insights
Media.net employs cutting-edge technologies like cross-format header bidding. Understanding these can give you a competitive advantage in leveraging similar technologies.
Legal and Ethical Compliance
Compliance with Media.net's terms of service and quality policies is essential. Data scraping must be conducted in a manner that adheres to these guidelines to ensure ethical practices.
Use Cases of Scraping Media.net
Competitive Analysis
Scraping Media.net provides insights into their ad offerings, pricing models, and market positioning. This competitive intelligence is invaluable for businesses aiming to understand their standing in the industry.
Market Research
Data from Media.net can reveal market trends and consumer preferences, helping businesses create an ideal customer profile and adapt their offerings accordingly.
Pricing Strategies
Scraping pricing data from Media.net can inform more competitive pricing strategies by providing a clear understanding of market rates for various ad types.
Sentiment Analysis
If available, user reviews or comments on Media.net can offer insights into market sentiment and customer satisfaction. This data can guide both Media.net and its competitors in identifying areas for improvement or capitalizing on strengths.
By incorporating data scraping into your business operations, you can streamline the entire process of gathering actionable insights for strategic decision-making.
Legal and Ethical Considerations

Navigating the legal and ethical landscape of the data collection process is crucial for anyone looking to gather data from Media.net.
While web scraping can offer invaluable insights, it's important to approach it responsibly to avoid any legal repercussions.
Respecting robots.txt
The robots.txt file is a standard used by websites to guide web crawling and scraping bots about which pages can or cannot be retrieved.
Before initiating any web scraping project on Media.net, it's imperative to consult the site's robot.txt file.
This file indicates the areas of the website that are off-limits and those that can be accessed for data scraping.
Ignoring the directives in this file can not only lead to your IP address being blocked but also expose you to legal risks.
Understanding Media.net's Terms of Service
Media.net's Terms of Service (ToS) is a legal agreement that outlines the rules, terms, and guidelines for using their platform.
It's crucial to read and understand these terms before you start scraping data from the site.
Violating the ToS could result in a range of consequences, from temporary suspension of your account to legal action.
Look for sections in the ToS that specifically address data scraping or automated access to the platform.
If the ToS explicitly prohibits web scraping, then you must obtain written permission from Media.net to proceed.
Ethical Guidelines for Web Scraping
Beyond legal considerations, ethical behavior is paramount when scraping data from any website, including Media.net. Here are some ethical guidelines to consider:
Minimize Server Load
Ensure that your web scraping activities do not overload or disrupt the services of Media.net.
Use rate limiting and make requests at a frequency that mimics human browsing behavior.
Data Usage
Be transparent about your intentions for using the scraped data. If the data will be published or used for commercial purposes, seek permission from Media.net.
User Privacy
If you are scraping user-generated content, be cautious not to collect any personal information unless it's absolutely necessary for your project.
If personal data is collected, it should be anonymized and securely stored.
Attribution
If you plan to publish the data or any insights derived from it, provide proper attribution to Media.net as the source of the data.
By adhering to these legal and ethical guidelines, you can conduct your web scraping activities in a responsible and respectful manner. This not only minimizes risks but also contributes to the integrity and credibility of your data analysis or business intelligence project.
Tools and Technologies
The success of a web scraping project often hinges on the tools and technologies employed.
By leveraging these tools and technologies, you can build a robust web scraping pipeline for gathering data from Media.net.
Whether you're a beginner or an expert, the right combination of these resources can significantly enhance the efficiency and effectiveness of your web scraping endeavors.
Programming Languages
Python
Python is a versatile language widely used for web scraping due to its ease of use and extensive libraries.
It allows for quick development and deployment of web scraping scripts, making it ideal for both beginners and experts with a lot of programming experience.
JavaScript
JavaScript, particularly Node.js, is another powerful language for web scraping.
It's especially useful when dealing with websites that rely heavily on JavaScript to load content, as it can interact with the DOM (Document Object Model) directly.
Libraries and Frameworks

BeautifulSoup
BeautifulSoup is a Python library that is excellent for web scraping beginners.
It allows for easy navigation and manipulation of HTML and XML documents, making data extraction straightforward.
Scrapy
Scrapy is a more advanced Python framework designed for web scraping and crawling.
It offers built-in support for handling various data formats and exporting scraped data, making it suitable for large-scale projects.
Selenium
Selenium is often used for scraping websites that are rich in JavaScript. It automates browser interaction, allowing you to scrape data that is dynamically loaded.
Proxy Services
Importance of Using Proxies for Scraping
Using proxies is crucial for large-scale scraping to avoid detection and IP blocking. Proxies also allow for geo-targeted scraping, which can be essential for gathering location-specific data.
Geonode Proxies
Geonode proxies offer a layer of anonymity and security, making them ideal for web scraping projects.
They help in bypassing IP bans and rate limits imposed by websites like Media.net.
Integrating Geonode Proxies into Your Scraping Code
Setting up Geonode proxies involves creating an account and then integrating it into your code.

Most programming languages and scraping libraries offer straightforward ways to set up proxy configurations.
For example, in Python, you can use the Requests library to easily integrate Geonode proxies.
Browser Extensions
Web Scraper
Web Scraper is a browser extension that allows for easy point-and-click web scraping.
It's excellent for small-scale projects and those who are new to web scraping.
Data Miner
Data Miner is another browser extension that offers pre-made data scraping "recipes."
It's useful for extracting data from websites without writing any code, although it may not be suitable for more complex scraping needs.
Setting Up the Environment
Before diving into the actual web scraping process, it's crucial to set up a conducive development environment.
This involves installing essential software and libraries that will be used throughout the project.
Installing Python and pip
-
Download Python. Visit the official Python website and download the latest version suitable for your operating system.
-
Installation. Run the installer and follow the on-screen instructions. Make sure to check the box that says "Add Python to PATH" during installation.
-
Verify Installation. Open your command prompt or terminal and type python--version to ensure that Python was installed correctly.
-
Install pip. Pip (Package Installer for Python) usually comes pre-installed with Python.
You can check its installation by typing pip--version in the command prompt or terminal.
Setting Up a Code Editor
- Download Visual Studio Code. Visit the Visual Studio Code website and download the version compatible with your operating system.
- Installation. Run the installer and follow the setup instructions.
- Extensions. Once installed, you can add extensions like Python, Beautify, and IntelliSense to enhance your coding experience.
Installing Required Libraries and Frameworks
Open your terminal and install the following Python libraries:
- BeautifulSoup:
pip install beautifulsoup4
- Scrapy:
pip install scrapy
- Selenium:
pip install selenium
Identifying Data Points
Navigating Through Media.net's Website
Before writing any code, spend some time navigating through Media.net's website to understand its structure and identify the data points you wish to scrape.
Understanding the Structure of Media.net Website
The Media.net website serves as a platform for contextual advertising and programmatic solutions. It caters to both advertisers and publishers, offering a variety of services to maximize revenue. The website is organized into several main sections, including:
- Home. Introduction to Media.net and its services.
- Marketplace. Information about the competitive demand from various sources to maximize yield.

- Contextual Ads. Details about Media.net's proprietary ad format that leverages search keywords for targeted advertising.
- Programmatic. Information on their next-gen cross-format header bidding platform.
- Buyers. A section likely dedicated to potential advertisers.
- About. Background information about Media.net.
- Sign In. For existing users to log into their accounts.
- Contact Us. For inquiries and support.
The website also provides additional information on Display Ads and Native Ads, explaining how they can benefit publishers.
Identifying Key Data to Scrape
Determine what specific data you want to scrape from Media.net. This could range from types of ads offered, pricing models, to blog posts and articles. Make a list of these data points as they will guide your scraping logic.
Writing the Code
Once your environment is set up and you've identified the data points you want to scrape, the next step is to write the code.
Web scraping can be done manually or through automated methods. Below, we'll explore both approaches and provide sample code snippets for each.
Manual Scraping
Steps and Limitations
Manual scraping involves navigating through the website and copying data manually into a spreadsheet or a similar storage medium.
While this method is straightforward, it's time-consuming and not practical for large datasets.
Automated Scraping
Automated scraping is the most efficient way to gather data, especially for large-scale projects. We'll look at how to scrape data using BeautifulSoup, Scrapy, and Selenium.
Using BeautifulSoup
Sample Code Snippets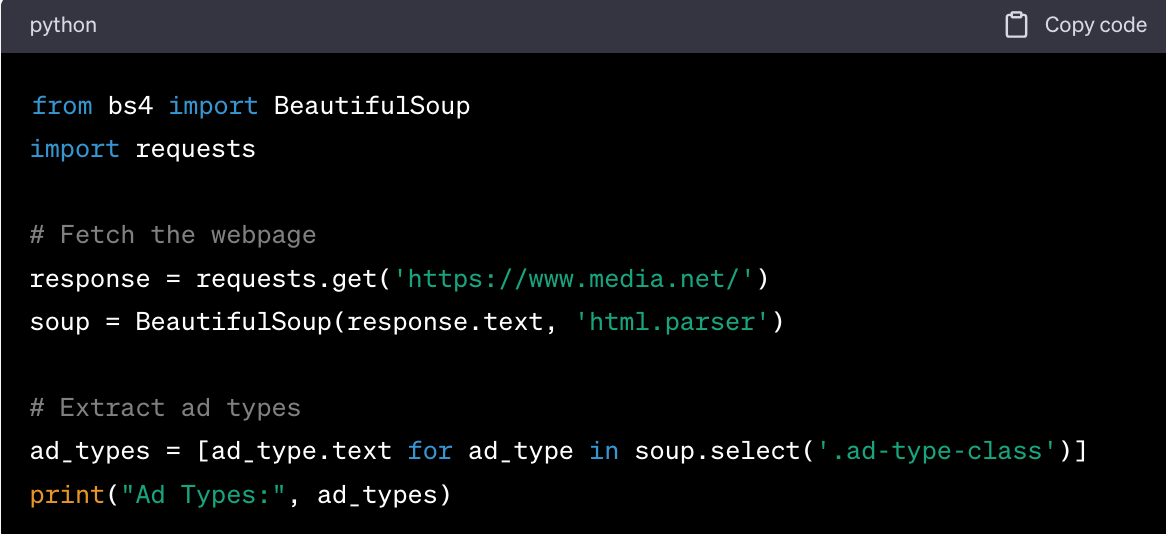
Explanation of Code
- Import the BeautifulSoup library and the requests module.
- Fetch the webpage content using
requests.get().
- Parse the HTML content using BeautifulSoup.
- Extract the ad types using the
.select() method, targeting the specific class that holds this information.
Using Scrapy
Sample Code Snippets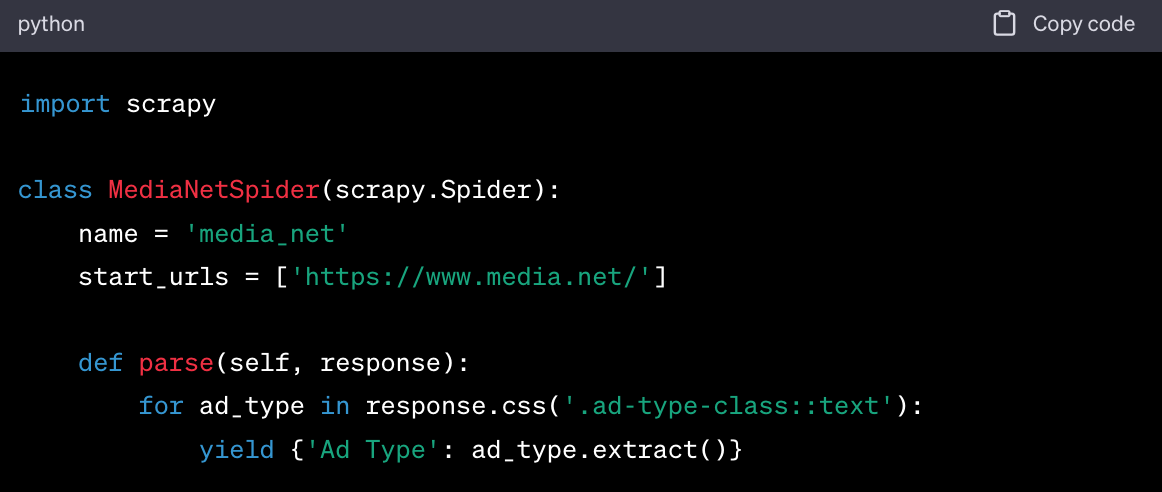
Explanation of Code
- Import the Scrapy library.
- Define a spider class that inherits from
scrapy.Spider.
- Specify the URL to scrape in
start_urls.
- Define the
parse method to extract the ad types using the .css() method.
Using Selenium
Sample Code Snippets
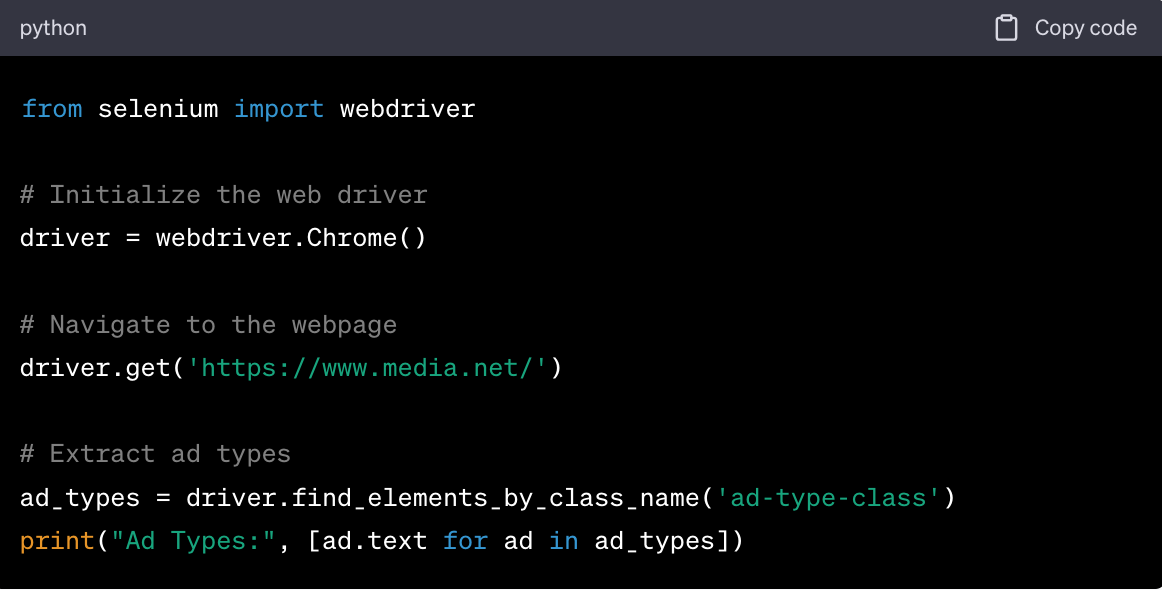
CSV
You can use Python's built-in csv library to store the scraped data in a CSV file.
Database
For more complex projects, storing the data in a database like MySQL or MongoDB is advisable.
By following these steps and using these code snippets as a guide, you can build a robust web scraping pipeline for gathering data from Media.net.
Using Self-Built Scrapers
Self-built web scrapers offer a higher degree of customization and control over the data you collect.
With programming knowledge, you can write specific lines of code to target unique elements on Media.net's website, allowing for more nuanced data collection.
Custom scraper models are ideal for those who have specific data needs that generic scraper tools may not be able to fulfill.
Using Data Extraction Services
Data extraction services often come with pre-built scraper APIs and tools designed for deep scraping of web content.
Scraping services can handle complex data extraction scenarios without requiring you to write lines of code.
They are particularly useful for businesses that lack programming knowledge but still want to gather valuable insights from platforms like Media.net.
Troubleshooting and FAQs
Web scraping is a powerful tool, but it comes with its own set of challenges.
Common Errors and Solutions
IP Being Blocked
Solution: Using proxies is a good way to circumvent getting your IP blocked.
Geonode offers a variety of proxy services that can help you scrape data anonymously, thereby reducing the chances of your IP being blocked.
Rate Limit Exceeded
Solution: Implement rate limiting in your code to control the frequency of your requests.
You can also use Geonode proxies to rotate IPs, which can help you avoid hitting rate limits.
Incomplete or Inaccurate Data
Solution: This usually happens when the website structure changes.
Always make sure to update your code according to the latest website layout.
Timeout Errors
Solution: Increase the timeout limit in your code.
Also, consider using Geonode proxies for more reliable connectivity.
People Also Ask

How to Scrape Media.net Without Getting Blocked?
Using Geonode proxies can help you scrape Media.net without getting blocked.
These proxies mask your IP address, making it difficult for websites to detect scraping activity.
Is Scraping Media.net Legal?
Always refer to Media.net's Terms of Service to understand their policy on web scraping. Generally, if a website's robots.txt allows it and you're not violating any terms, it's usually permissible.
How Can I Scrape Media.net Faster?
Using a more efficient library like Scrapy can speed up the scraping process.
Additionally, Geonode proxies can provide faster connections.
What Are the Best Libraries for Scraping Media.net?
BeautifulSoup, Scrapy, and Selenium are commonly used libraries for web scraping, each with its own set of advantages.
How Do Geonode Proxies Enhance Web Scraping?
Geonode proxies offer IP rotation, high-speed data center proxies, and residential proxies, making them ideal for web scraping.
They help in bypassing IP bans and rate limits, thereby enhancing the efficiency of your web scraping tasks.
Best Practices
Rate Limiting
Always implement rate limiting in your code to avoid overwhelming the server. This is not just courteous but also helps you avoid being blocked.
IP Rotation
Use Geonode proxies for IP rotation. This allows you to make requests through different IP addresses, reducing the likelihood of getting blocked.
Data Storage and Usage
Store the scraped data in a structured format like CSV or a database. Always respect the data's terms of use, especially if you plan to publish it.
Attribution
If you're using the data for research or reporting, always provide proper attribution to Media.net as the source of the data.
By adhering to these best practices and troubleshooting tips, you can make your web scraping project more effective and less prone to common issues.
Wrapping Up
Web scraping is an invaluable tool for gathering data from Media.net, offering insights that can be critical for various business applications such as competitive analysis, market research, and pricing strategies.
Throughout this article, we covered the essential steps for setting up your scraping environment, writing the code, and troubleshooting common issues.
We've also emphasized the importance of adhering to legal and ethical guidelines, with a special mention of how Geonode proxies can enhance your scraping efforts by providing anonymity and bypassing rate limits.
Next Steps

Data Cleaning and Analysis
Once you've successfully scraped the data, the next step is to clean and analyze it. Data cleaning involves removing duplicates, handling missing values, and converting data types.
After cleaning, you can proceed to analyze the data using statistical methods to derive actionable insights.
Strategic Implementation
The insights gained from the data can be strategically implemented in your business.
Whether it's adjusting your pricing models or identifying new market opportunities, the data you've gathered can serve as a valuable resource for decision-making.
Monitoring and Updating
Web scraping is not a one-time activity. Websites update their content and structure regularly, so it's essential to keep your scraping code updated.
Monitoring your scraping process will help you quickly identify and fix any issues that arise.
Additional Resources
Tutorials
- Web Scraping using Python: A Comprehensive Guide
- How to Use Proxies for Web Scraping
Documentation
- BeautifulSoup Documentation
- Scrapy Documentation
- Geonode Proxy Services
Forums for Community Support
- Stack Overflow
- Reddit Web Scraping Community
- Geonode Community Forum
By following the guidelines and best practices outlined in this article, you're well on your way to becoming proficient in web scraping. The data you gather from Media.net can offer you a competitive edge, provided you use it responsibly and ethically.
