Benefits of Scraping Walmart Data
One of the biggest retailers, Walmart operates a chain of hypermarkets, discount department stores, and grocery stores. It has a vast online presence with millions of products ranging from groceries, clothing, home goods, electronics, and more — making Walmart an incredibly valuable data source for web scraping.
Walmart scraping can serve a multitude of purposes, particularly for businesses and researchers. Here are some some practical applications of scraping data from Walmart:
• Market Research. Walmart's vast product offerings provide a comprehensive view of the market across numerous categories. By scraping this data, you can gain insights into product trends, consumer preferences, and pricing strategies.
• Competitive Analysis. Data scraped from Walmart can be used to understand what products are being sold, at what price, and how they are being marketed. This information can help you position your own products competitively.
• Price Monitoring. You can use scraped data to monitor Walmart's product prices in real-time, so you can adjust own prices accordingly and stay competitive.
• Product Assortment Optimization. By analyzing the range of products offered by Walmart, you can optimize your own product assortment to better meet consumer demand.
• Sentiment Analysis. Reviews and ratings on Walmart's website provide a wealth of information about consumer sentiment towards products. You can use this data can be used to improve product quality and customer service
Effortless Walmart Scraping with Geonode
Geonode's Scraping API is a powerful and user-friendly tool designed to simplify web scraping tasks. With a range of key features, it empowers users to efficiently extract large amounts of data from websites like Walmart without the need for writing complex lines of code.
Some of its standout features include:
• Debug Mode. Offers detailed information in a JSON response format, helping users understand how websites handle scraping requests and saving time and resources.
• JavaScript Rendering. Facilitates the scraping of Single Page Applications with dynamic element capture, ensuring comprehensive data extraction.
• Custom JS Snippet Execution. Allows developers to interact with forms, buttons, and other JavaScript-generated elements for greater control over the scraping process.
• Rotating Proxies. Employs a large proxy pool to avoid IP bans and bypass geo-restrictions, enhancing the reliability of data retrieval.
• Geotargeting. Ensures access to more websites without detection as a scraper.
• Screenshot API. Enables easy capture of web page screenshots for testing, troubleshooting, and documentation purposes.
• Pricing per GB. Offers cost-effective pricing and control over scraper expenses.
• Response Formats. Offers flexibility in choosing between HTML or JSON formats for integrated application use.
• Data Collection from HTTP Responses. Effortlessly collects specific data, such as JSON responses, to extract the required information.
• Scraping Mode. Provides various scraping modes for optimal performance and efficiency tailored to different scraping needs.
How to Scrape Walmart Data with Geonode
Understanding Walmart's Website Structure
Walmart is one of the largest retailers in the world; its website an expansive e-commerce platform with a well-structured and organized layout featuring billions of product pages. Understanding its structure is crucial for efficient and effective web scraping. Here's a basic overview of how data is organized on the Walmart website:
• Homepage. The homepage provides a general overview of what Walmart offers. It contains various categories of products, promotional offers, and more.
• Category Pages. When you click on a category from the homepage or the navigation menu, you're taken to a category page. These pages list products under a specific category, such as Electronics, Clothing, or Home Goods. Each category page has multiple subcategories for more specific product types.
• Product Listings. Each category or subcategory page contains a list of products. Each product list includes basic information such as the product name, price, image, and customer rating.
• Product Pages. Clicking on a product from the listing takes you to the individual product page. These pages contain detailed information about the product, including a more detailed description, product attributes, additional images, customer reviews, and often a list of related products.
• Search Functionality. The website also has a search bar that allows users to search for specific products. The search results are displayed in a similar format to the product listings on category pages.
When scraping Walmart's website, it's important to note that the data is primarily located in these areas. The product pages, in particular, are likely to be the most valuable, as they contain the most detailed information.
However, Walmart's website is dynamic; some content is loaded using JavaScript after the initial HTML page is loaded, which can make scraping more challenging. Good thing Geonode's Scraping API can handle JavaScript rendering and avoid this issue.
Identifying Key Data Points to Scrape
When scraping an e-commerce website like Walmart, the key data points you might want to extract will depend on the specific requirements of your project. Here are some common data points that are often valuable:
• Product Name. The product title is one of the most basic yet crucial pieces of information. It helps identify the variety of products the website features.
• Price. The price of the product is another critical data point. Competitor prices can be used for price comparison, tracking price changes over time, or identifying pricing trends.
• Images. Images provide a visual representation of the product. They can be useful for various purposes, such as image recognition tasks or providing visuals in a product catalog.
• Description. The product description provides detailed information about the product, including its features, specifications, and other relevant details.
• Product Reviews and Ratings. Reviews and ratings give insight into customer satisfaction and product quality. They can be used for sentiment analysis or to gauge public opinion about a product.
• Product Category. The category or subcategory of the product can provide context about what kind of product it is and where it fits in the broader product range.
• Product SKU or ID. The SKU or ID is a unique identifier for each product. This can be useful for tracking specific products.
• Availability Status. Information about whether the product is in stock, out of stock, or available for pre-order can be valuable for supply chain analysis or market research.
• Shipping Information. Details about shipping options and costs can be important for understanding the full cost of a product.
• Seller Information. If the product is sold by a third-party seller, information about the seller might be relevant.
Setting Up the Environment
Here's a step by step guide in setting up the environment for Geonode's Scraping API:
1. Create an Account on Geonode. The first step is to create an account on Geonode's website. This will give you access to their API and other services.
2. Get Your API Key. Once you've created an account and signed in, you can find your API key in your account settings or dashboard. This key is used to authenticate your requests to the API.
3. Install Necessary Libraries. Depending on the programming language you're using, you may need to install certain libraries to send HTTP requests and handle the responses.
• HTTP Client Library: To send requests to Geonode's API and receive responses, you'll need an HTTP client library. The specific library you'll use can depend on your programming language. For example, if you're using Python, you might use the Requests library. If you're using JavaScript, you might use Axios or Fetch.
• JSON Parsing Library: Geonode's API typically returns data in JSON format, so you'll need a library to parse this data. Most modern programming languages have built-in support for JSON parsing. For example, in Python, you can use the json module, and in JavaScript, you can use JSON.parse().
• Development Environment: You'll need a development environment to write and run your code. This could be a text editor like Sublime Text or Atom, or an integrated development environment (IDE) like PyCharm or Visual Studio Code.
4. Set Up Your Development Environment. Make sure your development environment is set up to send requests to the API and handle the responses. This might involve setting up a new project in your preferred integrated development environment (IDE) or text editor.
5. Test the API. Before you start building your web scraper, it's a good idea to test the API to make sure everything is working correctly. You can do this by sending a simple GET request to the API and checking the response.
6. Read the API Documentation: Geonode's API documentation will provide detailed information about how to use the API, including the available endpoints, request parameters, response formats, and more. Reading this documentation will help you understand how to use the API effectively.
Fetching a Walmart Product Page
Fetching a Walmart product page using Geonode's Scraping API involves sending an HTTP GET request to the API with the URL of the product page you want to scrape. Here's a general outline:
1. Identify the Product Page URL. Identify the URL of the Walmart product page you want to scrape. You can do this by navigating to the product page in your web browser and copying the URL from the address bar.
2. Prepare the API Request. Construct the API endpoint URL, which includes the base URL of Geonode's API, the endpoint for fetching a web page, and any necessary parameters. One of the parameters will be the URL of the Walmart product page you want to scrape.
3. Send the API Request. Send the API request using your HTTP client library. This will involve calling a function or method provided by the library, passing in the API endpoint URL, and setting the method to GET.
4. Handle the API Response. After you send the API request, the API will return a response. This response will contain the data from the Walmart product page, typically in HTML format. You'll need to handle this response in your code, which might involve parsing the HTML and extracting the data you're interested in.
Here's an example of how you might do this in Python using the Requests library:
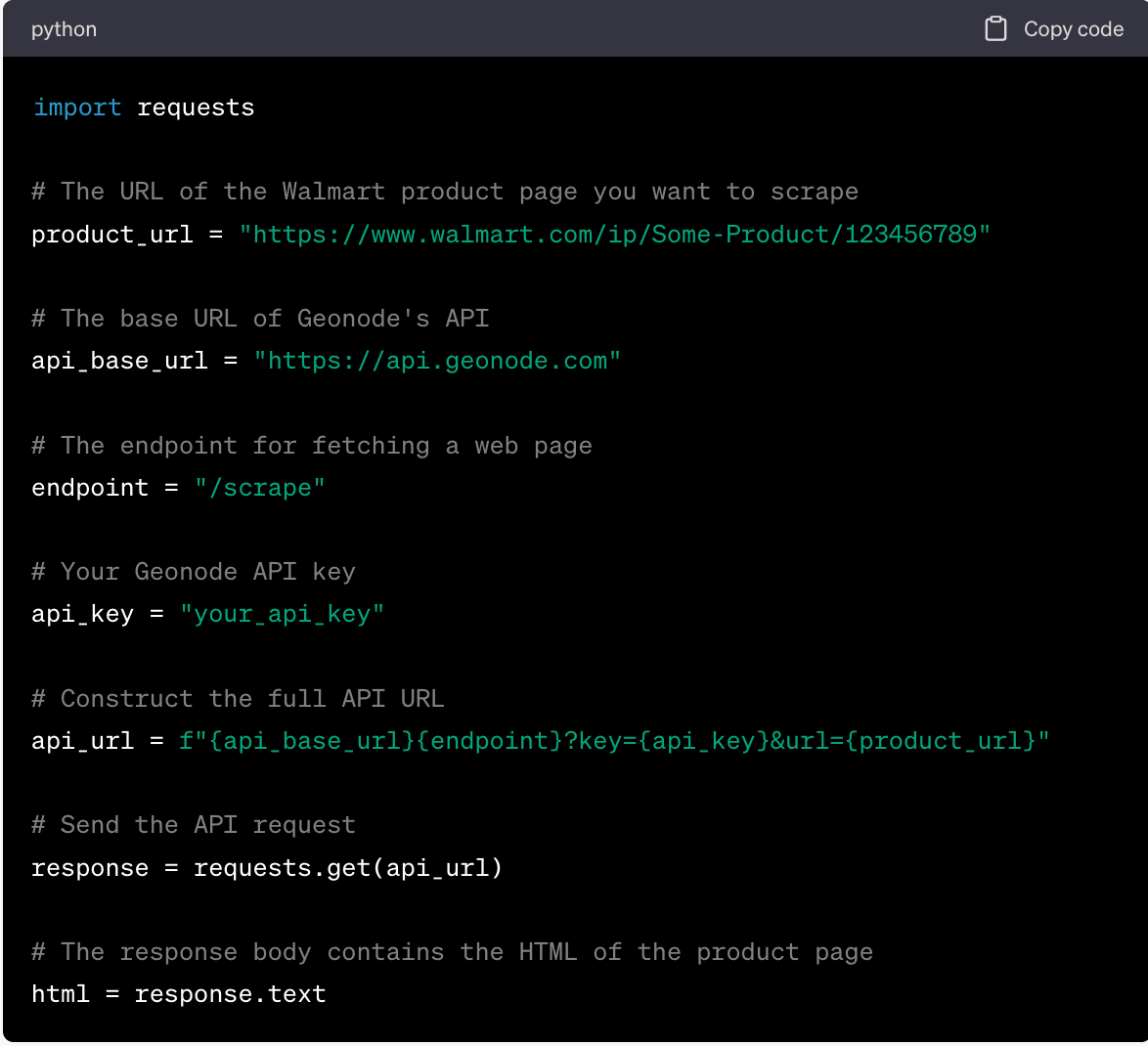
Extracting Data from the Product Page
Once you've fetched a Walmart product page using Geonode's Scraping API, the next step is to extract the key data points from the page. This typically involves parsing the HTML of the page and selecting the elements that contain the data you're interested in.
Here's a general outline of how you might do this:
1. Parse the HTML. The first step is to parse the HTML of the page. This involves converting the HTML string into a structure that you can navigate and search. The specific method for doing this can depend on your programming language and the libraries you're using. For example, in Python, you might use the BeautifulSoup library to parse the HTML.
2. Identify the Data Points. Next, you'll need to identify the HTML elements that contain the data points you're interested in. This typically involves inspecting the HTML of the page and finding the tags, classes, or IDs of these elements. You can do this using the developer tools in your web browser.
3. Select the Elements. Once you've identified the elements, you can select them from the parsed HTML. This typically involves calling a function or method provided by your HTML parsing library, passing in the tag, class, or ID of the element. This will return the element and its contents.
4. Extract the Data. After you've selected the elements, you can extract the data from them. This typically involves calling a function or method provided by your HTML parsing library, passing in the element. This will return the data contained in the element.
Here's an example of how you might parse HTML in Python using the BeautifulSoup library:
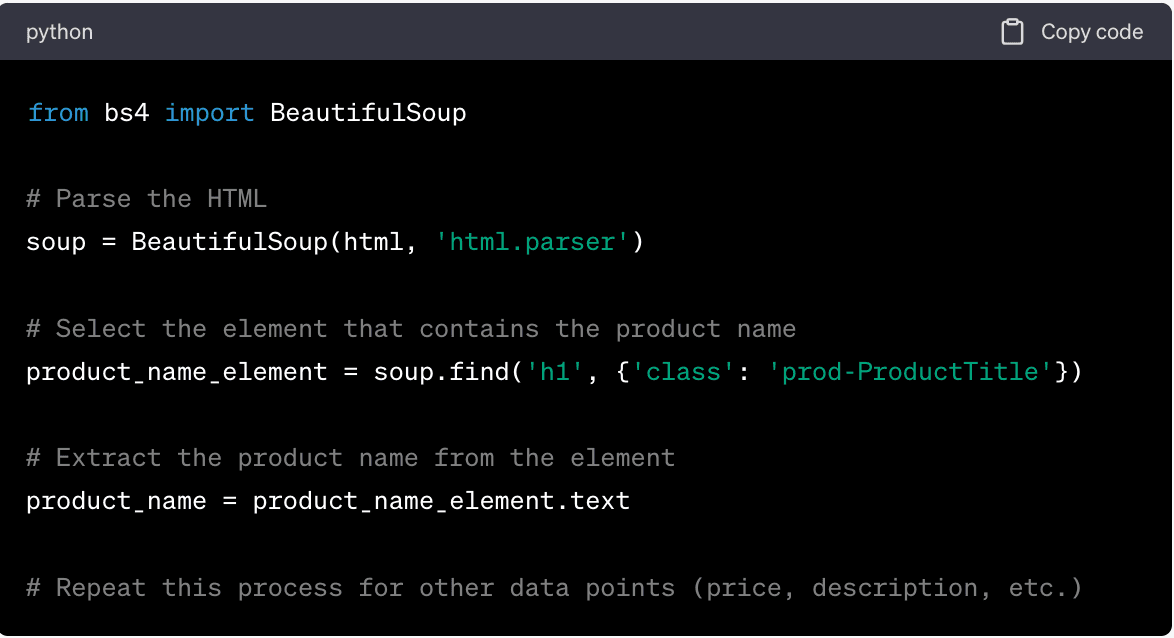
(This is a basic example and the actual implementation may vary depending on the specific structure of the Walmart product pages and the features and capabilities of your HTML parsing library. Always refer to the official documentation for your library for the most accurate and up-to-date information.)
Parsing the HTML and JSON Data
Parsing HTML and JSON data are common tasks in web scraping. Parsing is the process of taking raw data (in this case, HTML or JSON text) and converting it into a format that's easier to work with in your programming language.
Parsing HTML
HTML is the standard markup language for creating web pages. It uses tags to denote different types of content, making it relatively easy to navigate and extract specific data.
Here's an example of how you might parse HTML in Python using the BeautifulSoup library:
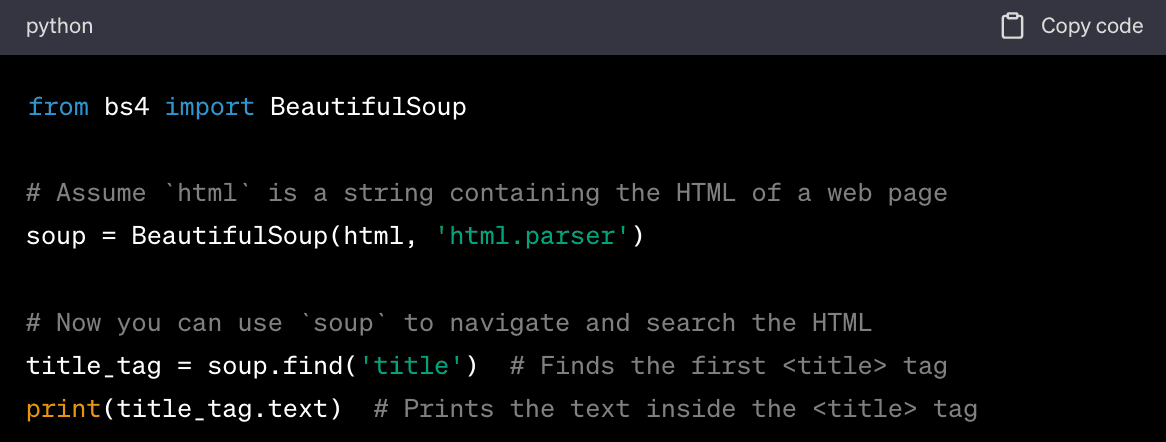
Parsing JSON
JSON (JavaScript Object Notation) is a lightweight data-interchange format that's easy for humans to read and write and easy for machines to parse and generate. It's often used by APIs to send data.
Here's an example of how you might parse JSON in Python:
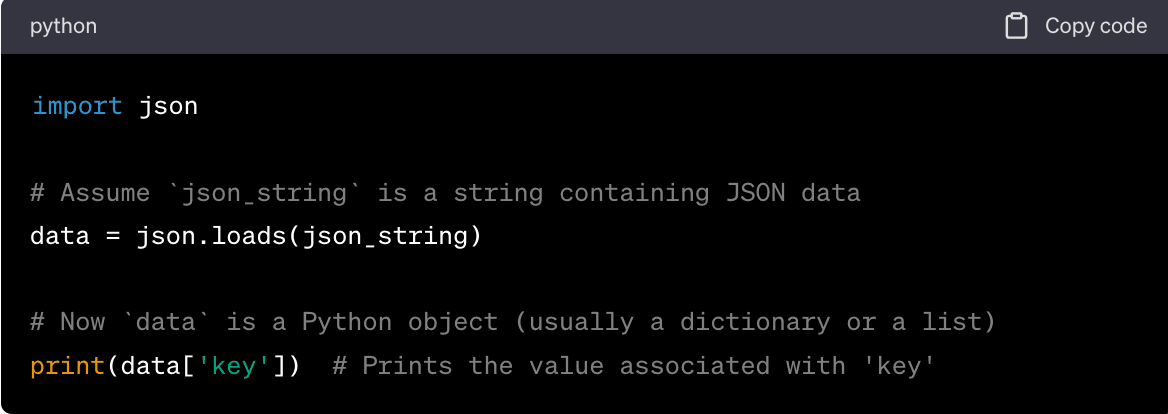
In both cases, the goal of parsing is to convert the raw HTML or JSON data into a format that's easier to work with in your programming language. Once the data is parsed, you can navigate it to find the specific pieces of data you're interested in.
Tips on Efficiently Managing Data
Managing large amounts of data efficiently is a crucial aspect of web scraping large e-commerce platforms like Walmart. Here are some tips on how to handle large datasets:
• Use a Database. Storing your data in a database can make it easier to manage, especially if you're dealing with large amounts of data. Databases are designed to handle large datasets and can provide features like indexing, which can make querying your data faster.
• Batch Processing. Instead of processing each data point as it's scraped, consider collecting your data into batches and processing each batch at once. This can be more efficient and can reduce the load on your system.
• Data Compression. If storage space is a concern, consider compressing your data. Many common data formats, like CSV and JSON, can be compressed to a fraction of their original size.
• Parallel Processing. If you're scraping multiple pages or websites at once, consider using parallel processing to speed up the process. This involves running multiple scraping tasks simultaneously, which can significantly reduce the total scraping time.
• Incremental Scraping. Instead of scraping all the data at once, consider scraping it incrementally. This involves keeping track of what data you've already scraped and only scraping new or updated data. This can be more efficient and can reduce the load on both your system and the website you're scraping.
• Use a Cloud-Based Solution. Cloud-based solutions can provide scalable storage and processing power, which can be especially useful when dealing with large amounts of data. Services like Amazon Web Services (AWS), Google Cloud, and Microsoft Azure offer various data storage and processing solutions that can handle large datasets.
• Data Cleaning and Validation. Clean and validate your data as early as possible in the data pipeline. This can include removing duplicates, handling missing values, and checking for data consistency. Cleaning and validating your data early can prevent errors and inefficiencies later on.
Remember, the goal is to manage your data in a way that's efficient, scalable, and suitable for your specific needs. The best approach can depend on the size of your dataset, the resources available to you, and the specific requirements of your project.
Avoiding Getting Blocked
While web scraping is a powerful tool for extracting data from websites, Walmart does not welcome this practice.
Here are some common reasons for getting blocked when scraping, along with tips on how to avoid them:
• Too Many Requests. Sending too many requests in a short period can overload Walmart's servers and negatively impact the website's performance. Often seen as a form of abuse, it's a common reason for getting blocked. To avoid this, limit your request rate and add delays between requests.
• Ignoring Robots.txt. The robots.txt file is a way for websites to communicate with web crawlers and scrapers. It specifies which parts of the website should not be scraped. Ignoring the rules in this file can lead to your scraper being blocked. Always check and respect the robots.txt file of the website you're scraping.
• Not Rotating IP Addresses. If all of your requests are coming from the same IP address, it can be a clear sign that you're scraping the website. Walmart will block your IP address if it's sending too many requests. To avoid this, consider using a pool of rotating residential proxies to distribute your requests across multiple IP addresses.
- Geonode's Scraping API uses a pool of rotating proxies. Each request you send through the API is made from a different IP address. This can help to avoid IP-based blocking and rate limiting, as it makes it harder for websites to identify and block your scraper. The rotation of IPs also help distribute your requests more evenly, reducing the load on any single server and making your scraping more efficient.
• Not Using a User-Agent String or Using a Suspicious One. The User-Agent string tells the website what type of device and browser is making the request. Websites like Walmart will block requests that don't include a User-Agent string, or that use a User-Agent string known to be associated with scrapers. Use a legitimate User-Agent string that mimics a real browser.
• Scraping Protected Data. Some data on a website may be protected by copyright or other legal protections. Scraping this data can lead being blocked, and can also have legal consequences. Always make sure you have the right to scrape and use the data you're targeting.
Of course, the best way to avoid getting blocked is to scrape responsibly. Respect the website's rules, don't overload the server, and always make sure you have the right to scrape and use the data you're targeting.
