Imagine you're handed a gigantic box filled with thousands of puzzle pieces – that's the data we gather in this digital era. It's massive, overwhelming, and at first glance, might not make much sense.
This is where data parsing comes into play. Think of it as your master puzzle solver that sorts through all those puzzle pieces, grouping them in a way that the picture starts to make sense.
Data parsing turns that confusing jumble of information into business-ready data that you can explore and learn from. It's like the backstage crew in a theater production, often unseen but critical for the show to go on.
In this article, we attempt to show how data parsing takes the spotlight, transforming raw data chaos into a story filled with insightful revelations.
Understanding Data Parsing
Data parsing is an important component in the field of data analysis. It transforms massive amounts of raw data into an organized data format to make it readable and understandable.
This transformation is crucial in this day and age where vast amounts of data are generated every second.
Parsing data allows us to structure information in a way that both machines and humans can understand. The result: smoother data processing and analysis that yield valuable insights.
The significance of data parsing lies in its ability to turn unstructured data to readable data formats that .
Whether it's for business analytics, software development, or research, parsed data provides clarity and aids in informed decision-making.
Real-world Examples of Data Parsing in Action
-
Web Scraping. When developers extract information from websites, the data often comes in HTML format.
Data parsing converts this HTML data into structured formats like JSON or XML, which are easier to analyze and store.
-
Log Analysis. System administrators often parse log files to extract specific pieces of information.
For instance, if a server crashes, parsing the log can help pinpoint the exact time of the crash and the events leading up to it.
-
E-commerce Platforms. When you search for a product on an online shopping site, the platform parses your search query to display the most relevant products.
This involves breaking down your input and matching it with product data.
-
Weather Applications. A weather app parses data from meteorological sources to present it in a user-friendly format that shows temperature, humidity, forecasts, and more.
-
Financial Transactions. Banking apps parse transaction data to display your account activity in an organized manner. It categorizes purchases, deposits, and other transactions for easy tracking.
In each of these examples, data parsing plays a pivotal role in ensuring that data is presented in a meaningful and organized manner.
Parsing data does not just facilitating efficient data analysis; it also enhances user experience.
The Mechanics of Data Parsing
Turning messy data into clear information involves specific steps.
These steps, or mechanics, help break down and organize the data in a way that's easy to understand.
Let's explore the main types of analysis used in the data parsing process:
Lexical Analysis
Lexical analysis forms the fundamental groundwork for data parsing.
The process involves scanning raw data to identify and categorize individual pieces, often referred to as tokens or individual lexical units.
Think of it as breaking down a sentence into words. Each word, or token, has a specific role.
In data parsing, lexical analysis identifies these tokens from the raw data, ensuring that the next stages of parsing can process them correctly.
Suppose we have the following raw data string:

Lexical Analysis Breakdown
In the lexical analysis phase, this string would be scanned and broken down into individual tokens. Here's how the process might look:
- "John" - Identified as a proper noun (a name in this case).
- "bought" - Identified as a verb.
- "3" - Identified as a number.
- "apples" - Identified as a noun.
- "for" - Identified as a preposition.
- "$" - Identified as a currency symbol.
- "5" - Identified as a number.
Each of these tokens is categorized based on its type and role in the data string.
The process of lexical analysis doesn't concern itself with the relationship between these tokens or the overall meaning of the string.
Instead, it focuses solely on recognizing and categorizing each piece of data with the goal of recognizing and categorizing each data so they can be used in the next stages of analysis.
Syntactic Analysis
Once the data is broken down into tokens, syntactic analysis comes into play.
This phase is about arranging these tokens in a way that they form a coherent structure, like arranging words to form meaningful sentences.
By creating this structure, syntactic analysis ensures that the data is organized in a manner that both machines and humans can interpret.
Remember the data string we used above?
Lexical analysis breaks it down into tokens:
Syntactic Analysis Illustrated
Using these tokens, syntactic analysis will structure them into a meaningful sequence, represented as a tree structure: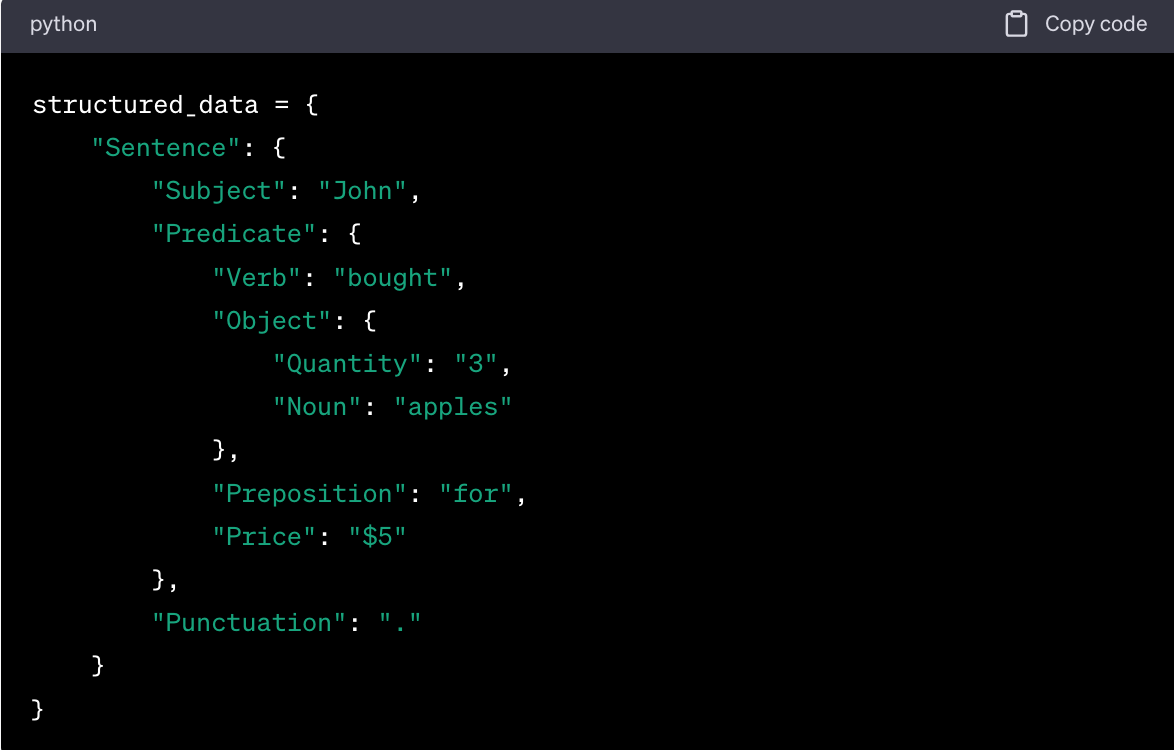
In this parse tree structure:
- "John" is identified as the subject of the sentence.
- "bought" is the main verb or action.
- "3 apples" is the object, further broken down into quantity ("3") and noun ("apples").
- "for" indicates a prepositional phrase.
- "$5" represents the price or cost associated with the action.
- "." is the punctuation marking the end of the sentence.
This structured representation, derived through syntax analysis, provides a clear hierarchy and relationship between the tokens, offering a deeper understanding of the original data string's meaning.
Semantic Analysis
The next step is semantic analysis.
This step is all about understanding the meaning behind the structured data.
It ensures that the relationships between different data pieces are clear and that the overall data makes sense.
Semantic Analysis Illustrated
After the syntactic analysis, we have a structured representation of the data.
Now, semantic analysis will interpret the meaning behind this structure.
Output:
In this semantic analysis, the structured data is interpreted to extract meaningful information.
The buyer's name, the action performed, the item purchased, the quantity of the item, and the total cost are all derived from the structured data.
The interpretation provides a clear understanding of the event described in the original data string.
Types of Data Parsing
When dealing with data parsing, it's important to know the two main types of data parsing: grammar-driven data parsing and data-driven data parsing.
Each of these methods has its own benefits and appropriate use cases.
Understanding these can help you choose the right method for your specific needs.
Grammar-driven Data Parsing
Grammar-driven parsing, as the name suggests, relies on predefined grammar rules to structure data.
This method is meticulous and precise, ensuring that the parsed data adheres strictly to the set guidelines.
For instance, programming languages often use grammar-driven parsers to interpret code, ensuring that developers follow the language's syntax and formal grammar rules.
While this approach offers high accuracy, it might not be as flexible when encountering unfamiliar or irregular data patterns.
To illustrate:
Imagine you're building a toy castle using a specific set of LEGO instructions.
Each step in the instructions tells you exactly which piece to use and where to place it.
If you follow the instructions precisely, you'll end up with a perfect castle.
However, if you try to use a piece that's not mentioned in the instructions or place it in a location not specified, the castle won't come together correctly.
In this analogy, the LEGO instructions represent the grammar rules, and the process of building the castle is like grammar-driven parsing.
Just as the LEGO castle requires specific pieces in specific places, grammar-driven parsing requires data to fit precisely within its predefined rules.
If the data doesn't fit, just like the wrong LEGO piece, the parsing process can't proceed correctly.
Data-driven Data Parsing
On the other hand, data-driven parsing employs statistical methods to interpret data.
Instead of relying solely on fixed rules, it uses patterns found in large datasets to make educated guesses about how to structure new data.
This approach is particularly useful when dealing with natural language processing tasks or when the data source is diverse and unpredictable.
By leveraging vast amounts of data, this method can adapt and provide broader coverage, making it more versatile in handling varied data inputs.
To illustrate:
Continuing with the LEGO analogy, imagine you have a mixed box of LEGO pieces without any specific instructions.
Instead of a set guide, you've observed many people building various structures with similar LEGO sets over time.
Based on these observations, you start to recognize common patterns and structures that people often build, like walls, towers, or bridges.
When you decide to build something from the mixed box, you rely on these observed patterns.
If you see a particular type of piece often used as a window or a door in past constructions, you might decide to use it the same way.
You're not strictly following a single set of instructions but using the knowledge gained from multiple previous builds to guide your construction.
In this scenario, the process of building based on observed patterns is similar to data-driven parsing.
Just as you use past LEGO constructions to guide your building, data-driven parsing uses patterns in existing datasets to interpret and structure new data.
It's flexible and adaptive, allowing for creativity and variation, much like building with LEGO without a fixed manual.
Data Parsing vs. Data Scraping
Data parsing and data scraping are two terms often used interchangeably, but they distinct data analysis process.
Understanding the differences between them, as well as their individual importance, is crucial for anyone working with data.
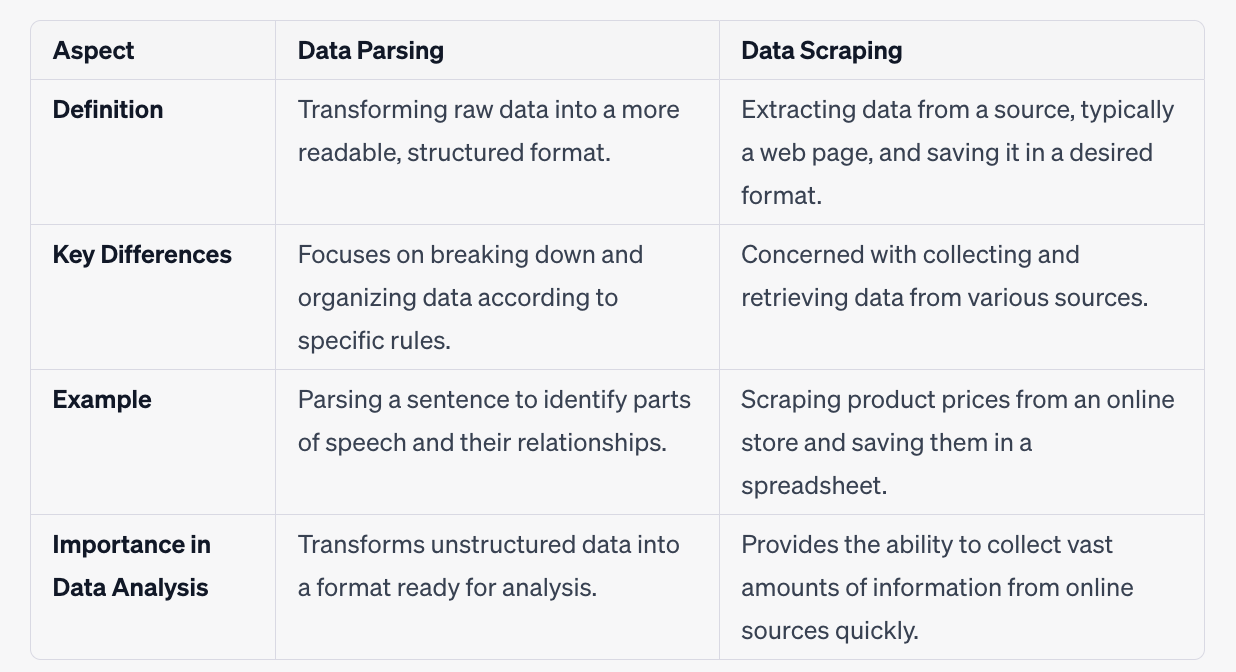
Data parsing and data scraping are distinct but complementary processes in the field of data analysis.
Parsing is about transforming and structuring data to making it ready for analysis, while scraping is about collecting and retrieving data from various sources.
Both are essential stages in turning raw information into actionable insights.
Applications of Data Parsing
Data parsing serves as a bridge between chaotic information and actionable insights, enabling modern industries to analyze and utilize data effectively.
This section explores the diverse applications of data parsing, highlighting its essential role in fields ranging from Natural Language Processing (NLP) to e-commerce, healthcare, financial analysis, and more.
-
Natural Language Processing (NLP). Data parsing in NLP involves breaking down human language into smaller parts, such as words and phrases, and understanding their relationships.
This process is crucial for various applications like speech recognition, where spoken words are converted into text, and machine translation, where text is translated from one language to another.
-
Data Transformation and ETL (Extract, Transform, Load) Processes. ETL processes use data parsing to take data from different sources and transform it into a uniform format.
This uniformity is essential for data analysis, as it ensures that data from various sources can be compared and analyzed together. It's a critical step in data warehousing and business intelligence.
-
Query Optimization in Databases. Data parsing is used to analyze database queries, understand their structure, and optimize their execution.
By choosing the most efficient way to retrieve data, parsing helps in reducing the time taken to answer queries, improving the performance of database systems.
-
Financial Data Analysis. In the financial sector, data parsing is used to analyze and interpret complex financial data.
It helps in converting financial reports and similar unstructured data into a readable format that can be used for various analyses like trend spotting, risk assessment, and investment decision-making.
-
Healthcare Data Standardization. Healthcare data often comes from various sources and in different formats. Data parsing helps the healthcare industry in standardizing this information, making it consistent across different systems.
This standardization is vital for patient care, as it ensures that medical professionals have accurate and uniform data.
-
Search Engine Optimization (SEO) Analysis. Data parsing plays a role in analyzing web pages and understanding their content, structure, and metadata.
This understanding helps in optimizing various elements of a webpage and improve its visibility online.
-
Social Media Data Analysis. Social media platforms generate vast amounts of unstructured data. Data parsing helps in structuring this data, making it possible to analyze trends, sentiments, and user behaviors.
This analysis is valuable for businesses looking to understand their audience and tailor their marketing strategies.
-
Scientific Data Interpretation. Scientific research often involves complex data in different file formats that needs to be interpreted accurately.
Data parsing helps in structuring this data, whether it's genomic information in biology or meteorological data in climate science, enabling researchers to derive meaningful insights.
-
Geographic Information Systems (GIS) Data Handling. GIS relies on spatial data that must be accurately parsed and structured.
Data parsing ensures that coordinates, map layers, and other geographical information are handled correctly, facilitating tasks like mapping, spatial analysis, and environmental monitoring.
-
E-commerce Product Information Structuring. E-commerce platforms deal with vast amounts of product information. Data parsing helps in structuring this information, ensuring that product descriptions, specifications, and prices are consistent across different platforms.
This consistency enhances the shopping experience for consumers, making product search and comparison easier.
Understanding Data Parsers
Data parsers are specialized software or algorithms, often referred to as parsing mechanisms, designed to convert inconsistent data formats into a structured and correct format.
They read the raw data, recognize specific elements, and organize them according to pre-defined rules or patterns.
This parsing procedure is essential for transforming high-quality data into a form that's understandable and usable for various applications.
There are two main kinds of data parsers: self-built and third-party parsers.
Self-built parsers are custom-designed by an organization to meet specific needs, while third-party parsers are pre-built solutions provided by external vendors.
Importance of Data Parsers
- Accessibility. By structuring data into the correct format, parsers make it accessible for analysis, reporting, and decision-making.
- Interoperability. Parsers enable data integration across different systems, ensuring consistency and compatibility, even with inconsistent data formats.
- Efficiency. Powerful data parsers speed up parsing tasks by automating the transformation, reducing manual effort.
- Accuracy. Parsers ensure that data is correctly interpreted, minimizing errors, and enhancing the reliability of the high-quality data.
Self-built Parsers
Self-built parsers are custom-designed by an organization to meet specific needs, making them a powerful tool for data processing.
Unlike third-party solutions, self-built parsers allow for the creation of dedicated parser systems that can be tailored to handle unique and complex solutions.
-
Dedicated Parser. Building an in-house parser allows an organization to create a dedicated parsing mechanism that aligns perfectly with its data structure and requirements.
This ensures that the parser is finely tuned to the specific data formats and patterns that the organization deals with regularly, leading to accurate analysis.
-
Ideal Solutions for Complex Needs. For business operations dealing with highly specialized or complex data, self-built parsers often emerge as ideal solutions that help make informed business decisions.
They can be designed to handle intricate data structures or to comply with stringent industry regulations and business requirements, providing a level of customization that third-party parsers might not offer.
-
Powerful Tool for Optimization. A self-built parser is not just a functional utility; it's a powerful tool that can be optimized to glean accurate insights for long-term business success.
By controlling every aspect of the parsing procedure, an organization can ensure that the parser operates at peak efficiency, handling large volumes of data without bottlenecks.
-
Challenges and Considerations. While self-built parsers offer many advantages, they also come with challenges.
Building a dedicated parser requires specialized knowledge and can be resource-intensive. The complexity of designing a parser that can handle complex solutions may also lead to higher development costs and longer implementation timelines.
Third-Party Data Parsers
Third-party data parsers are pre-built solutions provided by external vendors, designed to assist organizations in the collection process of data and its transformation into a structured format.
Some of the most popular third-part parsers include:
- Apache Commons CSV - A library for reading and writing CSV files.
- Jackson - A JSON parser for Java that offers high performance and flexibility.
- Beautiful Soup - A Python library for web scraping, allowing HTML and XML parsing.
- TinyXML - A lightweight XML parser, suitable for smaller projects or embedded systems.
- Pandas - A Python library that provides data structures for efficiently storing large datasets and includes functions for data parsing.
These parsers come with various functionalities and can be used for different purposes, such as:
- XML Parsing. Third-party parsers can handle XML documents, translating the string of commands into a format that's easily readable and manageable.
- Document Parsing. Document parsers are used to extract valuable information from various document formats.
- Proxy Parsing. When dealing with web data and communication protocols, a proxy parser can be employed to manage the data flow.
Benefits
- Simple Terms. Many third-party parsers are designed in simple terms, making them accessible to users without deep technical expertise. This simplicity often accelerates the collection process.
- Granular Control: While not as customizable as self-built parsers, many sophisticated parsers offer granular control, allowing for depth analysis and specific data handling.
- Dedicated Server Options: Some third-party parsers provide dedicated server options, ensuring complete control over the parsing environment and enhancing performance.
- Constant Maintenance: Vendors often provide constant maintenance, ensuring that the parser is always up to date with the latest communication protocols and standards.
Challenges
- Limited Customization. Unlike custom scripts in self-built parsers, third-party solutions might not offer complete control for highly specific needs.
- Potential Security Concerns. Depending on the parser, there might be concerns regarding data security and compliance with industry regulations.
- Licensing and Costs. Utilizing a proper parser from a third-party may involve licensing fees and ongoing costs for maintenance and support.
The Future of Data Parsing
The future of data parsing is marked by continuous evolution and innovation, driven by emerging technologies and methodologies.
Integration with cloud computing, real-time parsing capabilities, enhanced security measures, and customizable solutions are paving the way for more scalable, flexible, and efficient parsing tools.
Artificial Intelligence (AI) and Machine Learning (ML) play a significant role in this transformation.
AI-powered parsers can not only structure data but also interpret its meaning, adding a layer of semantic understanding that allows for more sophisticated analytics.
In addition, the demand for real-time analytics and the growing concern for data privacy are pushing the development of more robust and agile parsing solutions.
The ability to parse data on the fly and the incorporation of robust security measures are becoming essential features of modern parsing tools.
The future of data parsing is promising, with technological advancements and the integration of AI and ML making parsing more automated, adaptable, and insightful.
These developments are set to make data parsing a more vital and dynamic component in the data-driven decision-making processes of the future.
Final Thoughts
Data parsing is more than a technical necessity; it's a strategic asset that can unlock actionable business insights.
By transforming raw, unstructured data into a structured and understandable format, data parsing allows businesses to analyze and interpret information that can drive decision-making and innovation.
Whether it's understanding customer behavior, improving operational efficiency, or uncovering new market opportunities, data parsing serves as a powerful tool for extracting meaningful insights.
By investing in proper parsing mechanisms, whether self-built or through third-party solutions, businesses can enhance their ability to make informed, data-driven decisions.
We encourage you to think beyond the numbers and see the stories and opportunities hidden within the data. With data parsing, you can explore, understand, and leverage information in ways that can transform your business leading to growth and success
