ETL pipelines are essential because they provide a streamlined approach to data processing, enabling businesses to gain insights into their operations and make informed decisions.
An example of an ETL pipeline is when used by a retail company to extract sales data from a database, transform it into a format suitable for analysis, and load it into a data warehouse for business intelligence purposes.
The pipeline could use a tool like Apache NiFi or Talend to extract the data, transform it using tools like Apache Spark or Python, and load it into a data warehouse like Amazon Redshift or Google BigQuery.
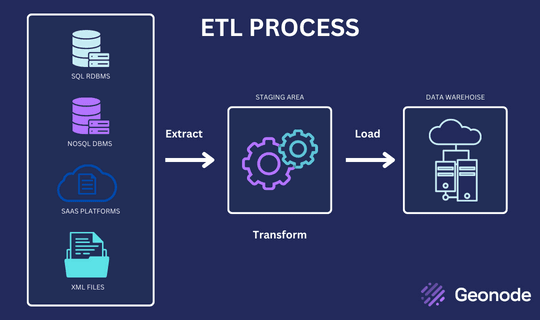
3 The Components of an ETL Pipeline
An ETL pipeline operation has three main components: extraction, transformation, and loading.
Extraction
The extraction phase involves pulling data from various sources, such as databases, cloud storage, APIs, and flat files. The extracted data can be in different formats, such as JSON, CSV, or XML.
Transformation
The transformation phase involves converting the extracted data into a usable format, cleaning it, and enriching it with additional information. This phase involves applying various data processing techniques, such as filtering, aggregating, joining, and sorting.
Loading
The loading phase involves storing the transformed data in a target destination, such as a database, a data warehouse, or a data lake. The loaded data can be used for various purposes, such as reporting, analysis, or machine learning.
Data Pipeline vs ETL Pipeline
A data pipeline is a general term that refers to a series of steps or processes used to move data from one system or application to another. It can include various components such as data ingestion, processing, storage, and analysis.
An ETL (Extract, Transform, Load) pipeline is a specific type of data pipeline used to extract data from one or more sources, transform it into a more useful or structured format, and load it into a destination system or application. ETL pipelines are commonly used for data warehousing, business intelligence, and analytics applications.
While ETL pipelines are a specific type of data pipeline, the two terms are often used interchangeably in practice. A data pipeline is generally any set of processes or tools used to move, process, and analyze data. In contrast, an ETL pipeline refers specifically to data extraction, transformation, and loading.
Types of ETL Pipeline
The two distinct types of ETL (Extract, Transform, Load) pipelines are:
Batch Processing: This type of pipeline involves processing large volumes of data in batches, typically daily or weekly. Data is extracted from source systems, transformed into a desired format, and loaded into a destination system in a batch process. Batch ETL is useful for data warehousing, business intelligence, and analytics applications.
Real-time Processing: This type of pipeline involves processing data in near-real-time as it is generated or received by the source system. Data is extracted from source systems, transformed in real time, and loaded into a destination system in a continuous process.
The Advantages of Using an ETL Pipeline
ETL pipelines offer several advantages, including:
Streamlined Data Processing
ETL pipelines provide a streamlined approach to data processing, enabling businesses to process vast amounts of data quickly and efficiently.
Improved Data Quality
ETL pipelines enable businesses to improve the quality of their data by eliminating duplicate records, correcting errors, and enforcing data standards.
Reduced Complexity
ETL pipelines reduce the complexity of data processing by providing a single interface for managing data integration tasks.
Improved Decision Making
ETL pipelines provide businesses with timely, accurate, and actionable insights into their operations, enabling them to make informed decisions.
ETL Languages
ETL pipelines can be implemented using a variety of programming languages and tools, depending on the specific requirements of the pipeline and the technologies being used. Some commonly used ETL languages and tools include:
SQL (Structured Query Language): SQL is a standard language used for managing and querying data in relational databases. ETL pipelines often use it to extract and transform data from databases.
Python: Python is a popular programming language used for a wide range of data processing and analysis tasks, including ETL pipelines. Python has many libraries and frameworks available for data manipulation, transformation, and loading, such as Pandas, NumPy, and Apache Airflow.
Java: Java is a widely used programming language that can be used for building ETL pipelines. Several Java-based ETL tools are available, such as Apache NiFi, Talend, and Apache Beam.
R: R is a programming language commonly used for statistical analysis and data visualization. It has many libraries and packages available for data manipulation and transformation and can be used for building ETL pipelines.
ETL tools: There are also many ETL tools available that provide a graphical user interface for building and managing ETL pipelines, such as Talend, Informatica, and Microsoft SSIS. These tools often support a variety of programming languages and data sources and can simplify the process of building and maintaining ETL pipelines.
Best Practices for Designing and Implementing ETL Pipelines
Businesses need to follow certain best practices to ensure the success of an ETL pipeline, including:
Define your Data Sources and Requirements
Before designing an ETL pipeline, businesses need to define their data sources and requirements. This involves identifying the data sources they need to integrate, their data formats, and the data quality standards they must meet.
Choose the Right Tools
Choosing the right tools is crucial for designing and implementing an ETL pipeline. In addition, businesses should consider the scalability, flexibility, and cost-effectiveness of their chosen tools.
Create a Clear Data Flow
A clear data flow is essential for designing an efficient and effective ETL pipeline. Furthermore, the data flow should be easy to understand, and the different stages of the pipeline should be clearly defined.
Implement Robust Error Handling
Robust error handling is essential for ensuring the reliability of an ETL pipeline. Therefore, businesses should implement error-handling mechanisms that can detect and resolve errors.
Test and Monitor Your Pipeline Regularly
Testing and monitoring an ETL pipeline regularly is essential for ensuring its effectiveness and identifying potential issues before they cause problems.
Common Challenges of ETL Pipelines and How to Overcome Them
Despite their advantages, ETL pipelines can also present certain challenges, including:
Data Inconsistencies
Data inconsistencies can occur when the data sources used in an ETL pipeline contain errors or inconsistencies. Data quality checks and cleansing mechanisms must be done to address this issue.
Data Quality Issues
Data quality issues can arise when the data used in an ETL pipeline is of poor quality or contains inaccuracies. Businesses should implement data quality checks and validation mechanisms to ensure the accuracy and consistency of the data.
Performance Bottlenecks
Performance bottlenecks can occur when an ETL pipeline is overloaded or when it fails to scale to handle increased data volumes. To avoid this issue, businesses should optimize their ETL pipelines for performance and scalability.
Limited Scalability
Limited scalability can occur when an ETL pipeline is unable to handle large volumes of data. ETL pipelines should be designed to be scalable and use distributed computing technologies to address this issue.
Conclusion
In conclusion, an ETL pipeline is a crucial component of a comprehensive data processing system. It enables businesses to collect, transform, and load vast amounts of data from various sources and gain insights into their operations. However, to design and implement an effective ETL pipeline, businesses must follow certain best practices, such as defining their data sources and requirements, choosing the right tools, creating a clear data flow, implementing robust error handling, and testing and monitoring their pipeline regularly.
People Also Ask
-
What is ETL VS Data Pipeline?
ETL and data pipeline are two related but distinct concepts. ETL stands for Extract, Transform, and Load, which refers to a specific process of extracting data from various sources, transforming it into a usable format, and loading it into a target destination. On the other hand, a data pipeline refers to a broader concept of moving data between different systems and applications, which can include ETL as a subset of the overall process.
-
Is SQL an ETL tool?
SQL is not an ETL tool per se, but it is commonly used in ETL processes to manipulate and transform data. SQL can be used to perform various data transformations, such as filtering, aggregating, and joining, which are essential components of the transformation stage in an ETL pipeline.
-
How do you create an ETL pipeline?
Creating an ETL pipeline involves several steps, including defining data sources and requirements, choosing the right tools, creating a clear data flow, implementing robust error handling, and regularly testing and monitoring the pipeline. Common tools for creating ETL pipelines include Apache Kafka, Apache Spark, and Talend Open Studio.
-
What is ETL in DevOps?
In DevOps, ETL refers to the process of integrating data from various sources into the DevOps pipeline. This can include extracting data from source code repositories, build tools, and test automation frameworks, transforming it into a usable format, and loading it into a target destination, such as a data warehouse or a business intelligence tool. ETL in DevOps is essential for providing teams with real-time insights into their software development processes and enabling them to make data-driven decisions.
References
Sharma, V. (2022, June 13). A Complete Guide on Building an ETL Pipeline for Beginners. Analytics Vidhya. Retrieved March 10, 2023, from https://www.analyticsvidhya.com/blog/2022/06/a-complete-guide-on-building-an-etl-pipeline-for-beginners/
What is an ETL Pipeline? (n.d.). Snowflake. Retrieved March 10, 2023, from https://www.snowflake.com/guides/etl-pipeline
What is an ETL Pipeline? Compare Data Pipeline vs ETL. (n.d.). Qlik. Retrieved March 10, 2023, from https://www.qlik.com/us/etl/etl-pipeline
