Accessing realty data from platforms like redfin.com has become a necessity for many businesses.
Whether you're a real estate analyst, a data scientist, or just a tech enthusiast, understanding how to scrape Redfin can offer invaluable insights.
This comprehensive guide will walk you through the best practices, tools, and methods to scrape Redfin efficiently and ethically.
Why Scrape Redfin?
Redfin: A Great Source of Real Estate Listings
Redfin is a prominent real estate website that offers listings of homes for sale, real estate market data, and other related services.
Founded in 2004, Redfin has grown to become one of the leading platforms in the realty industry, providing users with a user-friendly interface to search for properties based on various criteria such as property type, location, price range, number of bedrooms, and more.
One of Redfin's distinguishing features is its detailed property pages, which provide comprehensive information about a property, including high-resolution photos, property history, and neighborhood insights.
Additionally, Redfin offers tools like the 'Redfin Estimate,' which gives an estimated market value for homes, and interactive map searches that allow users to explore properties in specific neighborhoods or regions.
For brokers, agents, or individuals looking to gather data on property listings, market trends, or other property details, Redfin is a valuable resource.
Importance of Real Estate Data
Real estate data is more than just numbers and listings; it's a reflection of the market's heartbeat.
Every property listed, every price change, and every sale tells a story about the community, the economy, and consumer behavior.
By scraping Redfin, one of the leading real estate platforms, real estate agents, and businesses can access a treasure trove of data.
This data can offer insights into property values, market trends, and community preferences.
In a world driven by data, having timely and accurate real estate information can be a game-changer for many stakeholders, from investors to urban planners.
Redfin Scraper Applications in Market Analytics
Market analysis is crucial for any business or investor looking to make informed decisions. With Redfin real estate data, analysts can:
- Spot Trends. With a real estate scraper, one can identify which neighborhoods are becoming popular, which are seeing a decline in interest, or where property values are skyrocketing.
- Demand Analysis. Real estate web scraping helps agents understand what homebuyers or renters are looking for. This could be in terms of property size, amenities, proximity to schools or workplaces, and more.
- Investment Decisions. For real estate investors, data can give feasible options about where to buy next, what kind of properties to invest in, or when to sell.
- Policy Making. For local governments and urban planners, understanding the real estate market can help in making decisions about infrastructure development, zoning laws, and urban renewal projects.
Ethical Considerations
While scraping provides a wealth of data, it's essential to approach it responsibly. Here are some ethical guidelines to consider:
Respect robots.txt. This file on the Redfin website indicates which parts of the site can be accessed and scraped. Ignoring it is not just unethical but can also lead to legal consequences.
Avoid Overloading Servers. Sending too many requests in a short time can slow down or crash the Redfin site. It's essential to space out requests to avoid disrupting the site's operation.
Data Privacy. Always be cautious about how you use the especially if scraped Redfin data, especially if it contains personal information. Misusing such data can lead to severe legal and ethical consequences.
Different Ways to Perform Redfin Real Estate Data Scraping
Web scraping has become an indispensable method for extracting valuable insights from online sources such as Redfin. Here are a few tools and techniques available, each with its unique strengths and limitations:
Using Python Libraries
-
- Requests and BeautifulSoup. This is a common combination for web scraping.
Requests fetches the web page, and BeautifulSoup parses the HTML content.
- Scrapy. A more advanced and powerful scraping framework that can handle complex scraping tasks, including handling sessions, cookies, and even simulating user interactions.
Using Web Scraping Services
-
- Geonode's Scraper API. Geonode offers a scraper API that can be used to interact with web pages and extract data. It allows for actions like clicking, scrolling, and typing, which can be useful for scraping dynamic content.
- Other extraction services. There are many providers that offer Redfin real estate data scraping services. A quick search query will help you narrow down your choices and eventually select one that's best for your needs.
Browser Automation Tools
-
- Selenium: A tool primarily used for testing web applications, but it's also powerful for web scraping, especially for websites that load content dynamically using JavaScript.
Manual Scraping Process
Manual scraping involves manually copying data from a website and pasting it into a desired format or tool.
This method, also referred to as screen scraping, is labor-intensive and time-consuming but can be used for small tasks or when automated scraping is not feasible.
Step-by-Step Guide for Scraping Redfin with Python
Step 1: Set Up Your Environment
Install Python. Ensure you have Python installed on your system. If not, download and install it from Python's official website.
Install Required Libraries. You'll need a few Python libraries to help with the scraping. Install them using pip. 
Step 2: Identify Allowed URLs
Here is a subset of allowed search URLs from Redfin's robots.txt: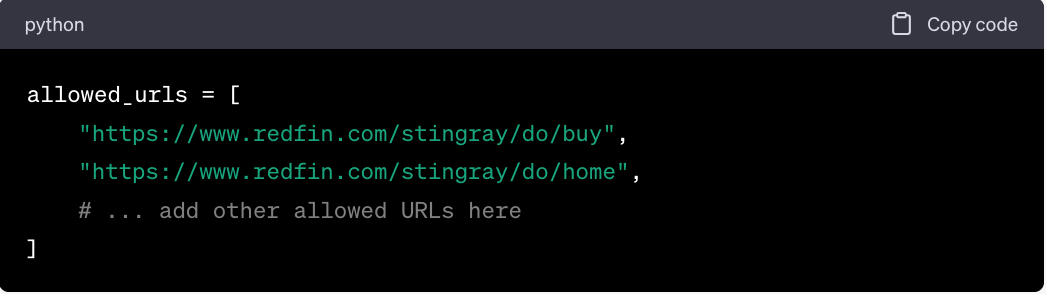
Step 3: Write the Scraper
Import Necessary Libraries 
Define the Scraper Function 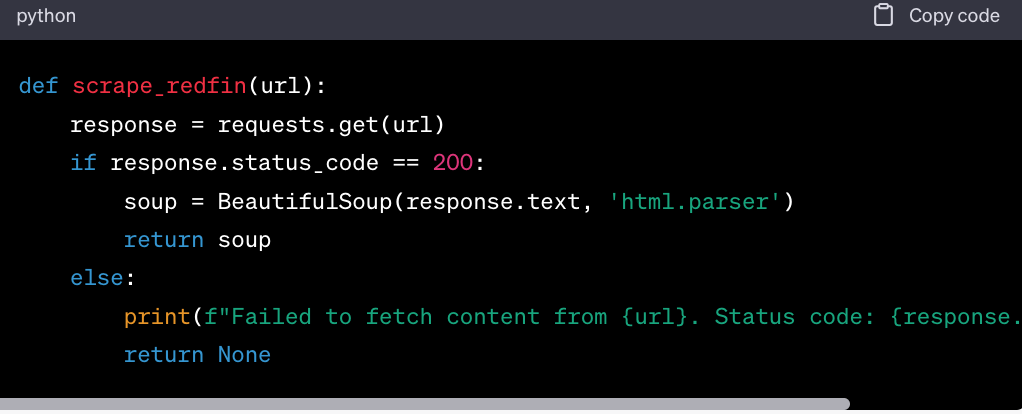
Loop Through Allowed URLs and Scrape 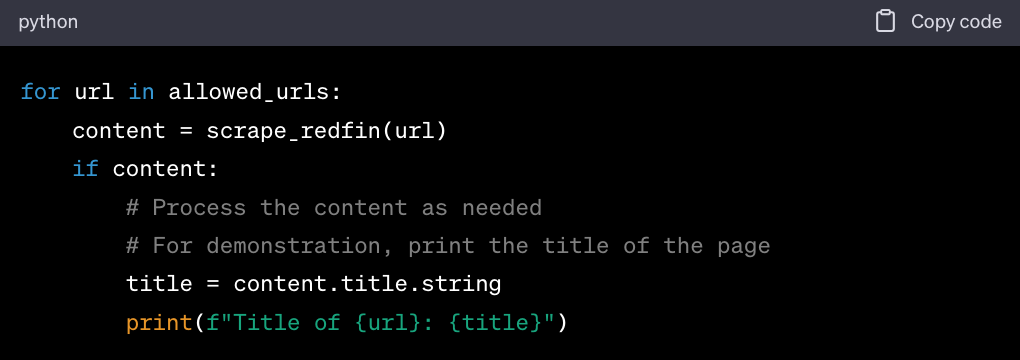
Step 4: Process and Store the Data
Once you've scraped the content, you can process it as needed. For instance, you might want to extract specific data points, clean the data, or store it in a database or file.
Extract Data. Use BeautifulSoup's functions like find(), find_all(), etc., to extract specific data from the scraped content.
Clean Data. Ensure the data is in the desired format, remove any unwanted characters or whitespace, and handle any missing or inconsistent data points.
Store Data. Depending on your needs, you can store the data in a database, write it to a CSV file, or save it in any other desired format.
How to Use Scrapy to Gather Data from Redfin
Step 1: Set Up Your Environment
Install Python. If you haven't already, download and install Python from Python's official website.
Install Scrapy.
Step 2: Create a Scrapy Project
Open your terminal or command prompt.
Navigate to the directory where you want to create your Scrapy project.
Run the following command:
Step 3: Define the Spider
Navigate to the spiders directory inside the redfin_project:
Create a new file named redfin_spider.py.
Open redfin_spider.py in your preferred text editor and add the following code: 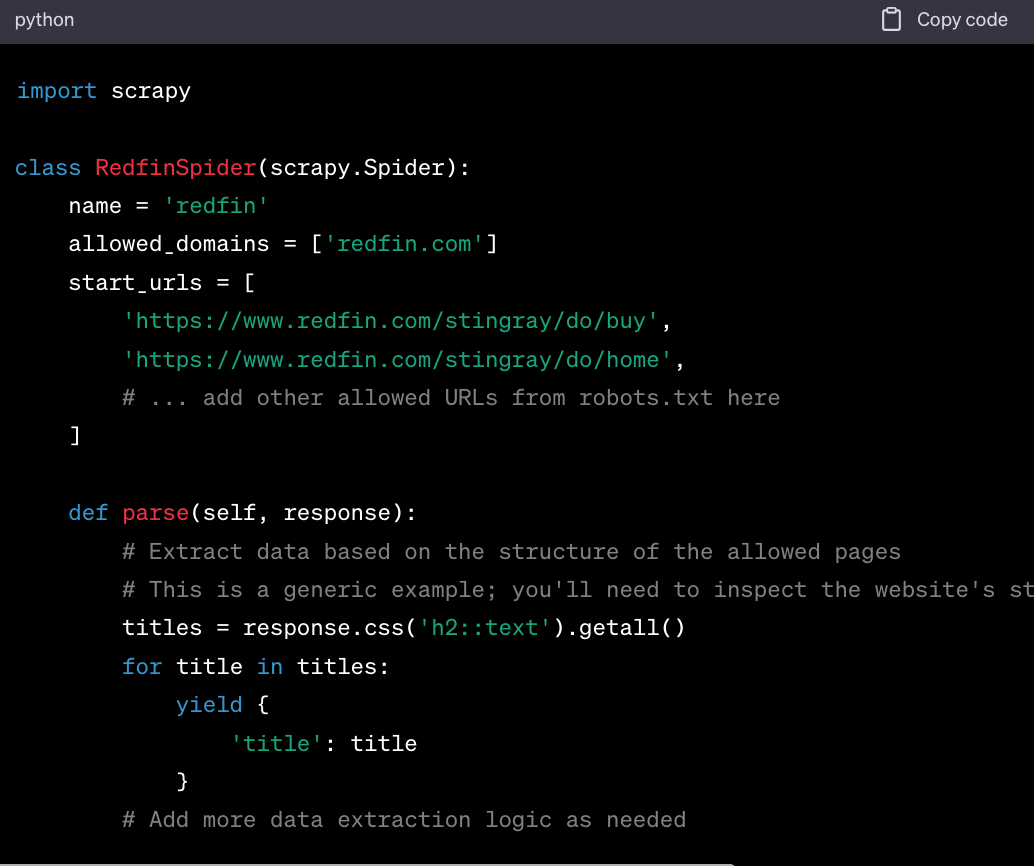
Step 4: Configure Scrapy Settings
Navigate back to the root of your Scrapy project (redfin_project).
Open settings.py in a text editor.
Modify or add the following settings to respect Redfin's robots.txt and avoid getting banned: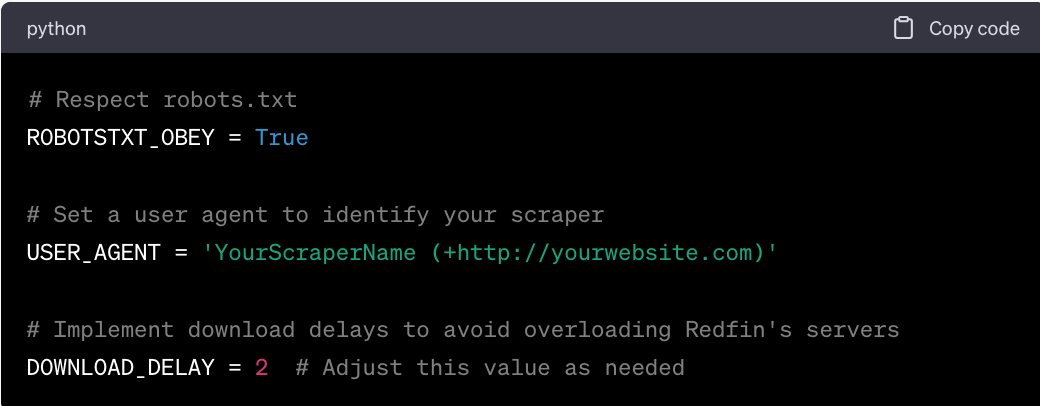
Step 5: Run the Spider
Open your terminal or command prompt.
Navigate to the root directory of your Scrapy project (redfin_project).
Run the spider with the following command: 
Step 6: Store the Scraped Data
By default, Scrapy will print the scraped data to the console. If you want to save the data to a file:
Modify the command to: 
This will save the scraped data in a file named output.json in the JSON format. You can also use other formats like CSV by changing the file extension.
Using Geonode Scraper API to Scrape Redfin Without Getting Banned

Step 1: Set Up Your Environment
Install Python: If you haven't already, download and install Python from Python's official website.
Install Required Libraries: You'll need the requests library to make API calls to Geonode's Scraper API:
Step 2: Obtain Geonode API Key
- Sign up or log in to Geonode.
- Navigate to your account settings or dashboard to obtain your API key. This key will be required for authentication when making requests to the Scraper API.
Step 3: Identify Allowed URLs from Redfin
Here's a subset of allowed URLs for scraping: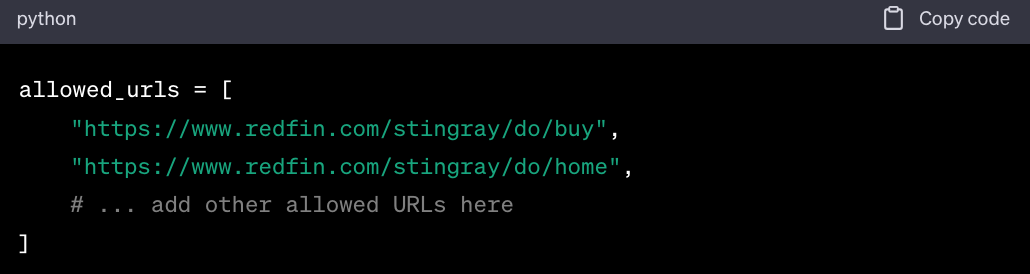
Step 4: Write the Scraper Script
Import Necessary Libraries:
Define the Scraper Function: 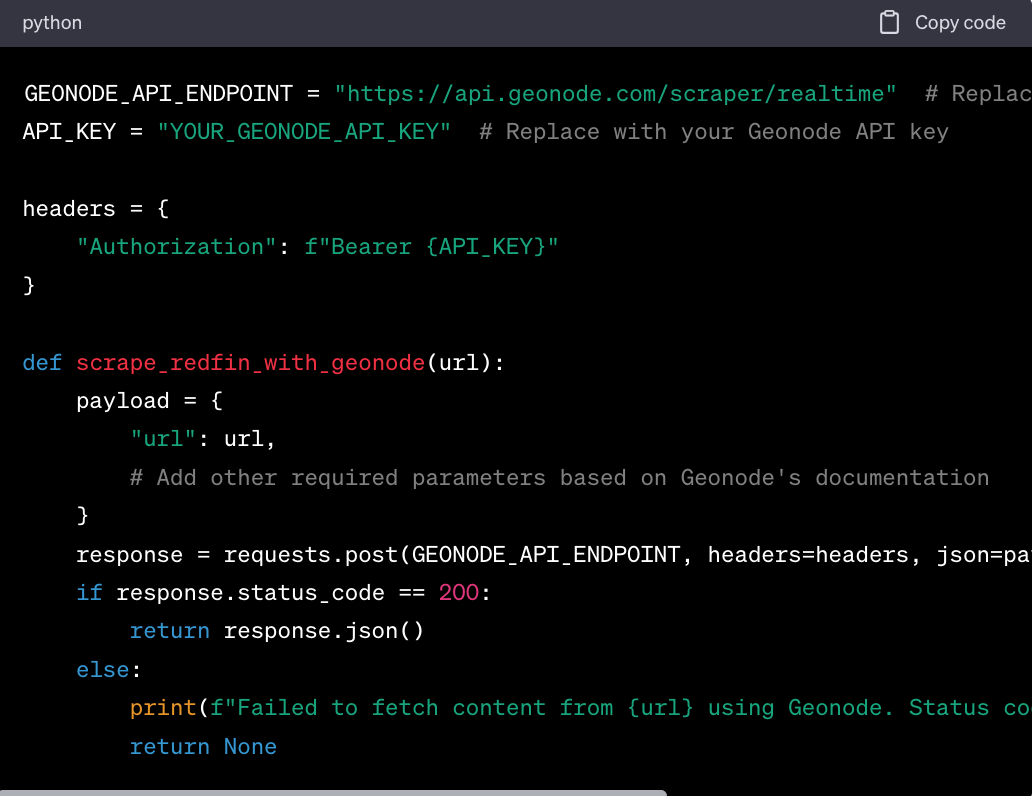
Loop Through Allowed URLs and Scrape:
Step 5: Process and Store the Data
Once you've scraped the content, you can process it as needed. For instance, you might want to extract specific data points, clean the data, or store it in a database or file.
- Extract Data. Depending on the structure of the data returned by Geonode, you might need to parse it to extract the desired information.
- Clean Data. Ensure the data is in the desired format, remove any unwanted characters or whitespace, and handle any missing or inconsistent data points.
- Store Data. Depending on your needs, you can store the data in a database, write it to a CSV file, or save it in any other desired format.
Additional Steps After Scraping
Regardless of the Redfin scraper tool you use, make sure to:
-
Review and refine the data. After your initial scraping, review the data you've collected. Ensure it's accurate and complete.
Refine your scraping logic if needed to capture any missed data or improve the quality of the data.
-
Do regular monitoring. If you plan to scrape Redfin regularly, monitor your scraper's performance and the data it collects.
Websites can change their structure, which might break your scraper. Regular monitoring will help you catch and fix any issues early.
Challenges & Solutions to Using Estate Data Scrapers
Web scraping is a powerful tool, but it comes with its own set of challenges, especially when targeting complex websites like Redfin.
Handling Dynamic Content
The Challenge: Modern websites like Redfin load content dynamically using JavaScript. Traditional scraping tools that only fetch the HTML source might miss out on this dynamically loaded content.
Solutions:
-
Browser Automation Tools. Tools like Selenium can simulate a real browser's behavior, allowing you to scrape content that's loaded dynamically.
With Selenium, you can wait for specific elements to load, interact with dropdowns, and even scroll pages to trigger content loading.
-
Inspect Network Calls. Using browser developer tools, inspect the network calls made by the website. Often, dynamic content is loaded via AJAX calls to internal APIs.
If you can identify these calls, you can directly request data from them, potentially getting data in a structured format like JSON.
Bypassing Anti-Scraping Measures
The Challenge: Redfin may employ anti-scraping measures to prevent automated bots from accessing their data. This can include CAPTCHAs, rate limits, or even IP bans.
Solutions:
-
Respect robots.txt. Always start by checking the robots.txt file of the website. It provides guidelines on which parts of the site can be accessed by web crawlers.
-
User-Agent Rotation. Rotate user-agents to mimic different browsers and devices. This can help bypass restrictions that target specific user-agents.
-
IP Rotation. Use Geonode residential proxies to rotate IP addresses. If one IP gets banned, the scraper can switch to another.
-
Rate Limiting. Introduce delays between requests to avoid sending too many requests in a short time. This can help prevent IP bans and show respect to the website's servers.
-
CAPTCHA Handling. Tools like 2Captcha or Anti-Captcha offer services to solve CAPTCHAs. Alternatively, consider using browser automation tools to manually solve CAPTCHAs when they appear.
Ensuring Data Accuracy and Integrity
The Challenge: Web scraping can sometimes result in incomplete or inaccurate data, especially if the website's structure changes or if there are inconsistencies in the way data is presented.
Solutions:
-
Regular Monitoring. Continuously monitor your scraper's performance. If you notice missing or inaccurate data, it might be due to changes in the website's structure.
-
Error Handling. Implement robust error handling in your scraper. If the scraper encounters an error, it should be able to log it and move on or retry the request, ensuring that temporary issues don't result in data loss.
-
Data Validation. After scraping, validate the data to ensure it meets certain criteria or formats. For instance, if scraping property prices, ensure the data is numeric and within a reasonable range.
-
Backup. Always keep backups of your scraped data. If you discover an issue with your scraper or the data it's collecting, having backups allows you to revert to a previous state.
By understanding and addressing these challenges, you can ensure that your web scraping endeavors are more successful, ethical, and resilient to the ever-evolving landscape of the web.
The Evolving Landscape of Web Scraping
Web scraping started as a simple means to extract static content from web pages.
Early websites were straightforward, and scraping them required little more than downloading the HTML and parsing it.
Today, websites like Redfin are dynamic, interactive, and packed with features. They load content on-the-fly, respond to user interactions, and even personalize content based on user behavior.
This evolution has made scraping more challenging but also more rewarding. Modern tools and techniques, from browser automation to machine learning, have risen to meet these challenges.
The Future of Real Estate Data Extraction
The real estate market is dynamic, with listings and price trends changing rapidly. The demand for real-time data and actionable insights will drive innovations in scraping technologies, pushing for faster and more frequent data extraction.
As data becomes more valuable, legal and ethical considerations around data extraction will come to the forefront.
We can expect more clear guidelines and regulations governing what can and cannot be scraped, ensuring that data extraction respects privacy and intellectual property rights.
Remaining Ethical
Web scraping is a powerful tool, but with this power comes the duty to use it ethically. As you scrape websites like Redfin for your various needs, always prioritize respect, integrity, and fairness.
By scraping you ensure that the pursuit of data never compromises the values that bind the digital community together.
