Why Scrape Twitter?
Twitter data, given its real-time nature and the vast amount of public opinion it encapsulates, can be used in a multitude of ways across various domains, such as:
• Brand Monitoring. Companies can use Twitter data to monitor what is being said about their brand in real time. This can help them respond promptly to customer complaints or queries, track the effectiveness of marketing campaigns, and understand public sentiment towards their brand. For example, a sudden spike in negative sentiments about a product could indicate a problem that needs to be addressed quickly.
• Trend Analysis. Twitter is often where new trends first emerge, making it a valuable resource for trend analysis. By analyzing the content of tweets, businesses can identify emerging trends in their industry, track the popularity of certain topics over time, and even predict future trends. This can inform business strategy, from product development to marketing and sales.
• Academic Research. Researchers in fields like sociology, linguistics, and political science can use Twitter data for a variety of purposes. For example, they might analyze user tweets to study language use, examine the spread of information or misinformation, or investigate the public's response to certain events or policies.
• Journalism. Journalists can use Twitter data to find breaking news, track the development of stories, and gauge public opinion on various issues. In some cases, tweets themselves can become news stories. For example, tweets from public figures can have significant impact and are often reported on in the media.
These are just a few examples of how data from billions of tweets can be used. The possibilities are vast and continue to grow as more and more people transition from other social media platforms to Twitter in sharing their thoughts and experiences.
Understanding Twitter Data
Before diving into the methods of Twitter scraping, it's essential to understand the four types of data available on Twitter and the potential insights that can be derived from them.
• Tweets. A tweet is the most basic unit of information on Twitter. It's a message posted by a user and can contain up to 280 characters. Each tweet carries a wealth of data, including the content of the tweet, the time it was posted, the number of likes and retweets it received, and the hashtags used. Analyzing tweet data can provide insights into trending topics, sentiment towards a particular subject, the reach of a hashtag, and more.
• Users. User data refers to the information related to Twitter accounts. This includes the username, profile description, location, number of followers and following, number of tweets, and the date the account was created. By analyzing user data, you can gain insights into the demographics of a user base, identify influencers in a particular field, or track the growth of a Twitter account over time.
• Entities. Entities in Twitter data refer to the objects that are associated with a tweet. This includes hashtags, user mentions, URLs, and media (photos and videos). Entities provide a way to understand the context of a tweet. For example, analyzing the hashtags associated with a tweet can help identify the topics being discussed, while examining the user mentions can reveal the network of interactions.
• Places. Thisdata refers to the geographical information associated with a tweet or a user. This could be the location from where a tweet was posted or the location specified in a user's profile. Analyzing places data can provide insights into geographical trends, the spread of information across locations, or the popularity of a topic in different regions.
Each type of data holds its own importance and can provide unique insights. For instance, tweet data can help identify trending topics and public sentiment, user data can reveal influencers and audience demographics, entities can provide context to the discussions, and places data can uncover geographical trends.
By understanding and analyzing these types of data, you can unlock a wealth of insights from Twitter. Whether it's for market research, brand monitoring, academic research, or journalism, Twitter data provides a rich and dynamic resource for understanding public opinion, tracking trends, and gaining a pulse on global conversations.
How to Scrape Twitter Data: Three Ways
1. Twitter API
Twitter's official API allows developers to interact with its platform programmatically. The API provides access to various types of data, including tweets, Twitter profiles, and more.
Why Use the Twitter API?
• Structured Data. Data returned by the API is well-structured and consistent, making it easier to handle and parse.
• Reliability. Because the API is provided by Twitter itself, it ensures reliability and continuity of service.
• Comprehensive Documentation. Twitter provides extensive documentation for its API, making it easier for developers to understand and use the API effectively.
Twitter API Limitations
• Rate Limits. To prevent abuse, Twitter imposes limits on its API for a certain time period. For instance, one could only make 900 requests every 15 minutes for user timeline requests with a user-authenticated app.
• Data Access. Not all data is accessible via the API. For example, you can only access the most recent 3200 tweets from a user's timeline.
• Costs. While Twitter provides a free tier for its API, it comes with significant limitations. Access to more data and higher rate limits requires a paid subscription, which can be quite expensive.
Steps in Using Twitter's API to Scrape Twitter Data:
Twitter's API is a powerful tool that allows developers to access a wide range of Twitter data programmatically. Here's a step-by-step guide on how to use it:
1. Set Up Developer Account
• Go to Twitter's Developer website (https://developer.twitter.com/).
• Click on the 'Apply' button.
• You'll be prompted to log in to your Twitter account. If you don't have one, you need to create one.
• Once logged in, fill out an application to apply for a developer account. The application asks for details about how you plan to use the API. Be as detailed as possible to increase your chances of approval.
• After submitting your application, wait for approval from Twitter. This can take a few days, so be patient.
2. Create An App and Get API Keys
• Log in to your Twitter Developer Account.
• Go to the 'Dashboard' and click on 'Create an app'.
• Fill out the form with details about your app. Provide a name, description, website URL, and tell Twitter how you plan to use the app.
• Take note of the API keys that you see on the page after your app is created. There are two sets of keys: the API key and secret, and the Access token and secret. You'll need these keys to authenticate your app when using the API.
3. Use Tweepy to Access the Twitter Scraper API
Follow these steps:
• Import the Tweepy library.
• Authenticate to Twitter using your API keys.
• Create an API object that you can use to interact with Twitter's API.
• Use the user_timeline method to get the most recent tweets from a user's timeline (in this case, 'twitter') and print the text of each tweet.
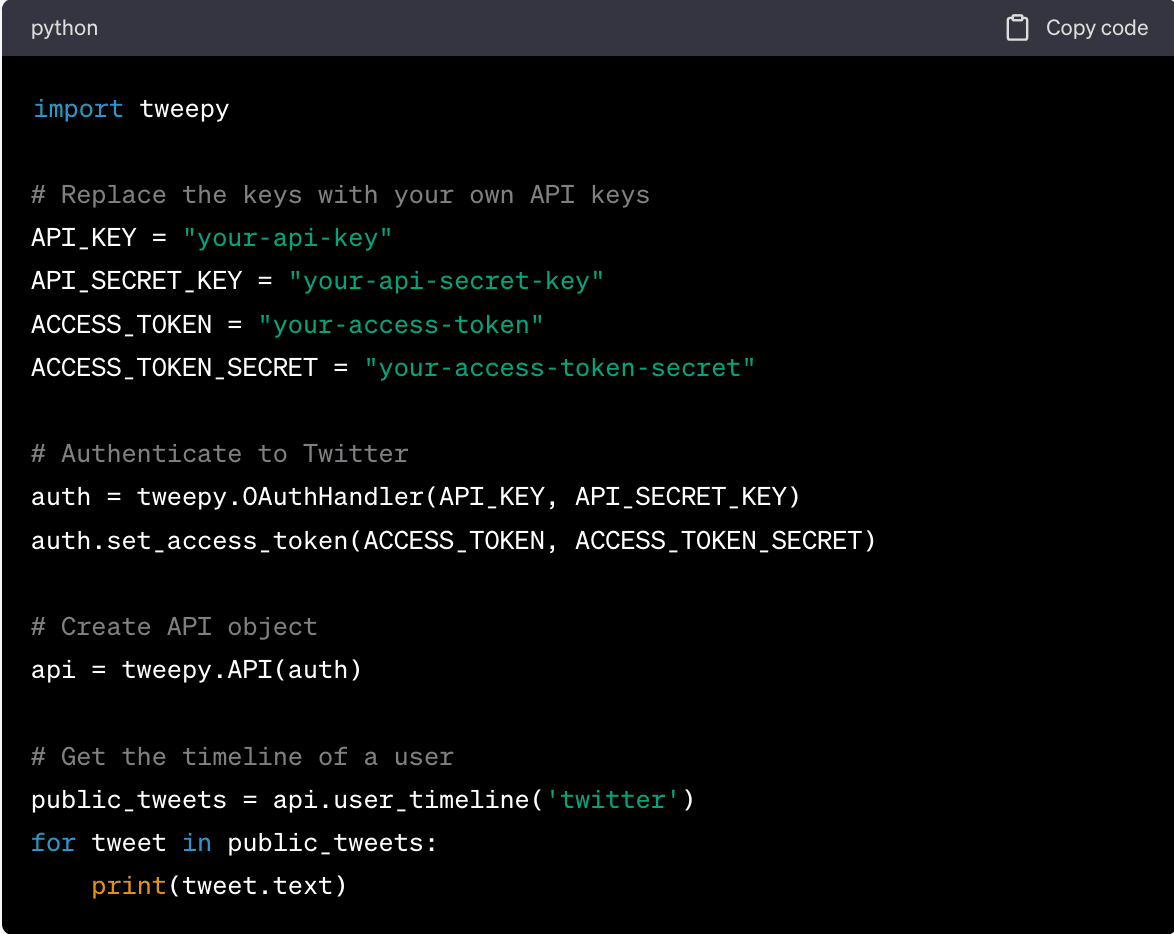
Remember to replace 'your-api-key', 'your-api-secret-key', 'your-access-token', and 'your-access-token-secret' with your own API keys. Also, replace 'twitter' with the username of the Twitter account you want to get tweets from.
This is a simple example, but Tweepy provides many more methods to access different types of Twitter data. Check out Tweepy's documentation for more information.
In summary, while the Twitter API provides a reliable and structured way to access Twitter data, it comes with limitations in terms of rate limits, data access, and costs. These limitations can be a significant hurdle for large-scale data extraction projects. In such cases, web scraping can be a more flexible and cost-effective alternative, which we will discuss in the next section.
2. Web Scraping Twitter with Python
Web scraping Twitter with Python is the process of automatically extracting data from Twitter's website using Python programming language. This process is often used to gather large amounts of data from Twitter that would be too time-consuming to collect manually.
Why Use Python?
• Powerful Libraries. Python has a rich ecosystem of libraries that simplify web scraping. Libraries like Tweepy, BeautifulSoup, and Scrapy can handle everything from making HTTP requests to parsing HTML and interacting with APIs.
• Ease of Use. Python's syntax is clear and concise, which makes it a good web scraping language. Even complex scraping tasks can be accomplished with relatively few lines of code.
• Data Analysis Tools. Python is also great for analyzing data. Libraries like Pandas, Numpy, and Matplotlib make it easy to clean, analyze, and visualize data scraped.
• Community Support. Python has a large and active community that makes finding help and resources online really easy. If you run into a problem, chances are someone else has already solved it.
Python Limitations
• Dynamic Content. Python's standard web scraping tools struggle with dynamic content loaded using JavaScript. There are ways around this, such as using a library like Selenium, but doing so adds another layer of complexity to the Twitter scraping project.
• Rate Limiting. Twitter imposes API rate limits, which can slow down your web scraping project. While there are ways around this, such as using multiple accounts or IP addresses, these methods are against Twitter's terms of service.
• Website Structure Changes. If Twitter changes the structure of its website or its API, your scraping code might stop working. You'll need to update your code to reflect these changes, which can be time-consuming.
Steps in Using Python for Web Scraping Twitter:
1. Set Up the Environment. Install Python and the necessary libraries if you don't already have them. For the sake of this example, we will use BeautifulSoup and Requests.
2. Send an HTTP request to the Twitter page you want to scrape.
The server responds to the request by returning the HTML content of the webpage.
3. Parse the data. Since the data is in HTML format, you'll need a parser which can parse and extract the data of interest.
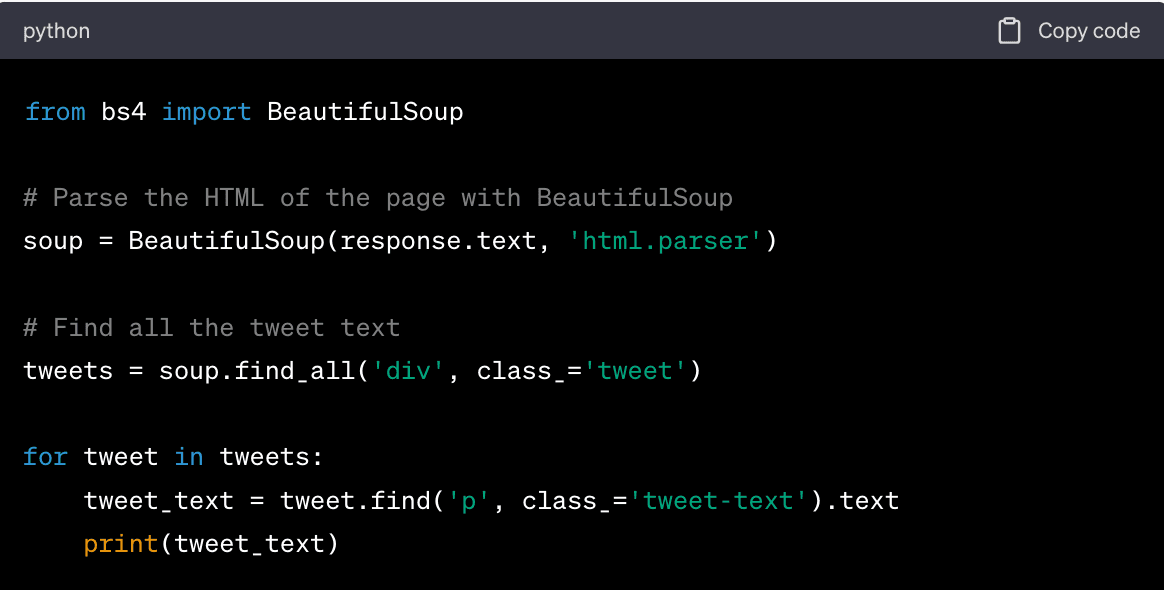
In this code, we first create a BeautifulSoup object and parse the HTML of the page. We then find all the div elements with the class 'tweet', which contain the tweets. For each tweet, we find the p element with the class 'tweet-text', which contains the text of the tweet, and print it.
4. Use querying methods to find specific data elements. With BeautifulSoup, for example, you can use methods like find_all() to locate header tags, paragraphs, or other elements.
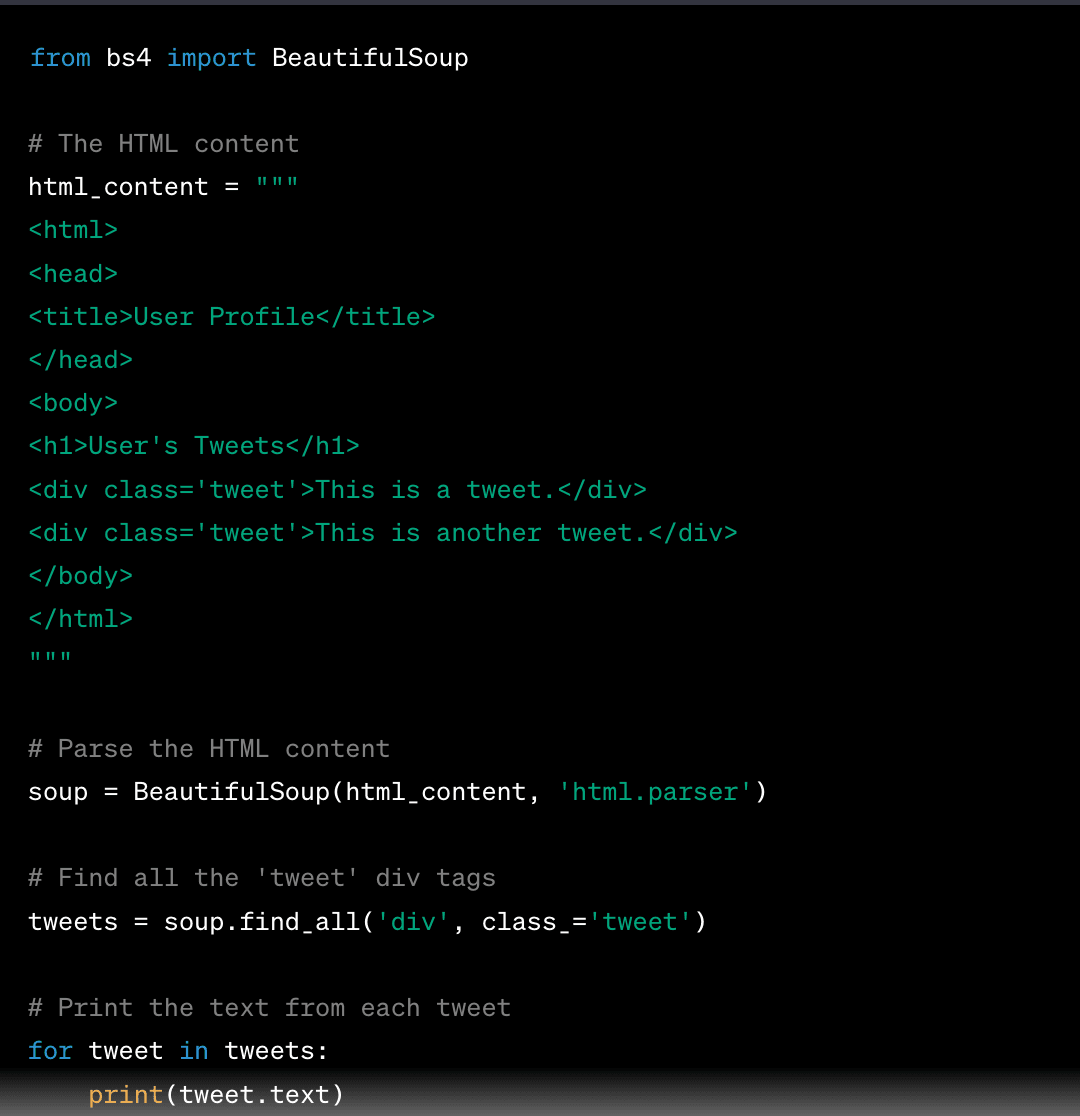
5. Save the data in the format you prefer, such as CSV, JSON, or a database. Here's how to save it in a CSV file using the Pandas library:
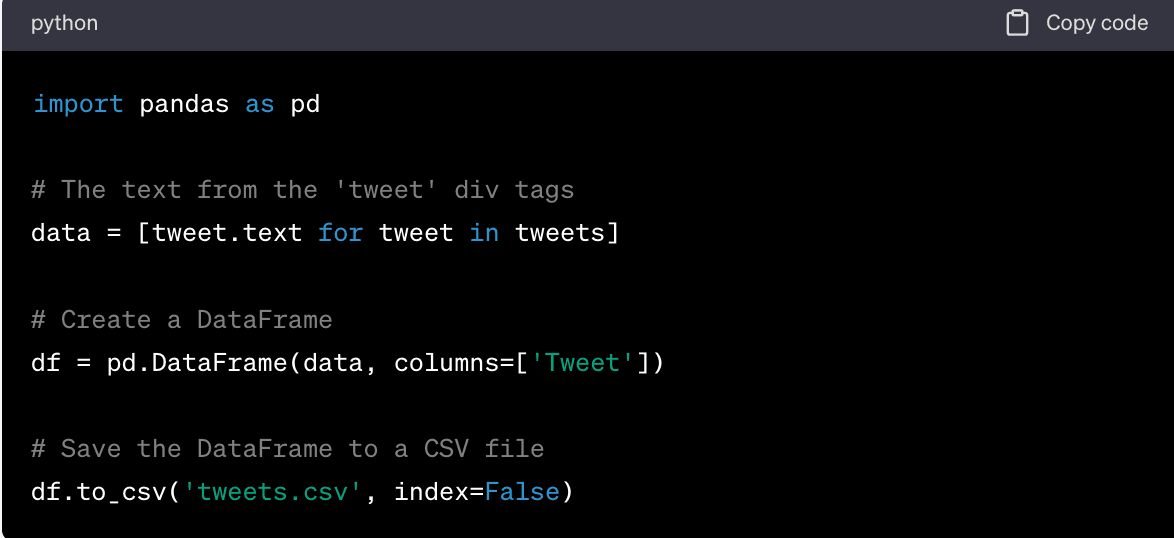
This will create a CSV file named 'tweets.csv' with a single column 'Tweet' that contains the text from the 'tweet' div tags.Here's a simple example of how you might scrape the text of a tweet using Python and BeautifulSoup:
3. Geonode
Geonode's Scraper API is a powerful tool that allows you to extract data from websites such as Twitter. It offers different scraping modes for optimal performance and efficiency.
Why Use Geonode's Pay-As-You-Go Scraper?
• Flexible Pricing. The pay-as-you-go model allows you to only pay for what you use. This can be more cost-effective than a subscription model, especially for irregular or low-volume usage.
• Scalability. This Scraper API is designed to handle both small and large-scale scraping tasks. This means you can scale up your scraping tasks as needed without worrying about hitting usage limits.
• Ease of Use. Geonode's Scraper API is easy to use, even for those without programming knowledge. It provides a simple way to extract data from Twitter.
• Advanced Features. Geonode's Scraper API offers a range of advanced features such as JavaScript rendering, custom JS snippet execution, rotating proxies, geotargeting, and more. These features can be very useful for complex scraping tasks.
• Real-Time and Callback Modes. The API provides two modes for scraping: Realtime Mode and Callback Mode. This gives you flexibility in how you receive your scraping results.
Limitations of GeoNode's Pay-As-You-Go Scraper
• Costs Can Add Up: While the pay-as-you-go model can be cost-effective for low-volume usage, costs can add up quickly for large-scale scraping tasks. It's important to monitor your usage to avoid unexpected charges.
• Learning Curve: While GeoNode's Scraper API is designed to be easy to use, there can still be a learning curve, especially for those new to web scraping or APIs in general.
• Dependent on GeoNode's Service: As with any third-party service, you're dependent on GeoNode's service for your scraping tasks. If there are any issues with their service, it could affect your scraping tasks.
• Legal and Ethical Considerations: Web scraping can be a legal gray area. While GeoNode's Scraper API makes it easy to scrape data, it's important to ensure that your scraping activities comply with the terms of service of the website you're scraping and any relevant privacy laws.
Steps in Using Geonode Scraper API for DataScraping Twitter
1. Set Up Your Request. To use the GeoNode Scraper API, you need to set up a request. This request should include the URL of the page you want to scrape (in this case, a Twitter page), and a set of configurations that control how the scraper behaves. Here's an example of how to structure your request:
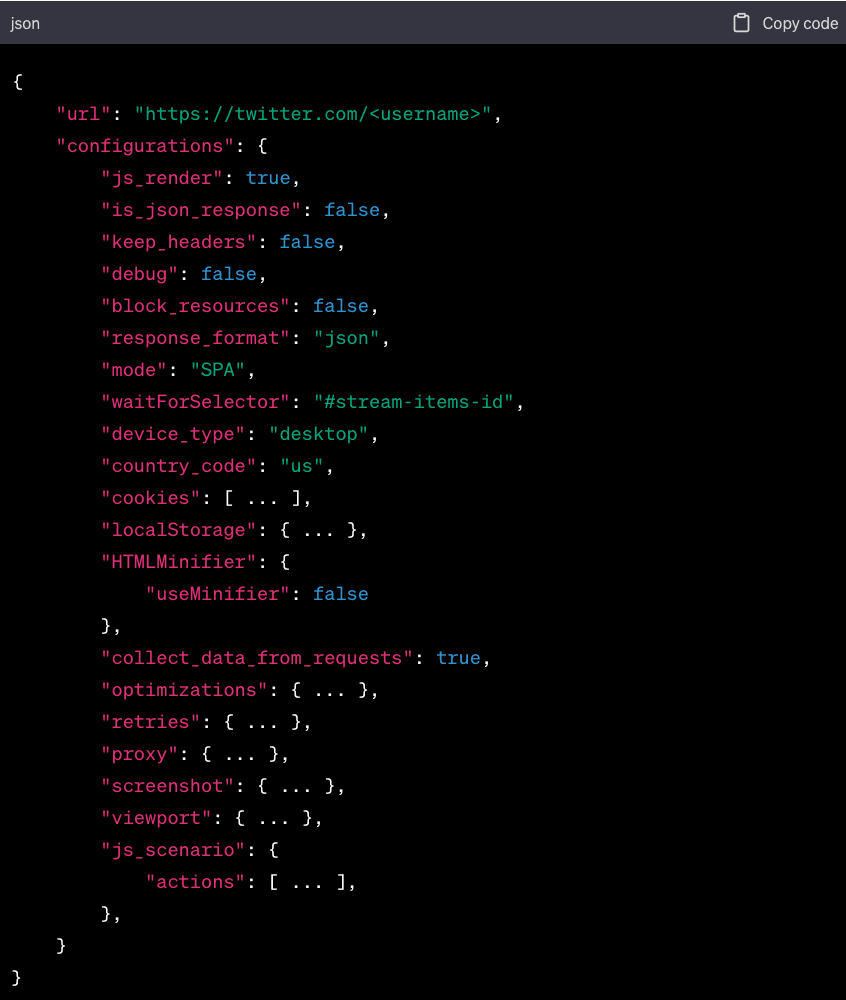
In this example, the url is the Twitter page you want to scrape. The waitForSelector parameter is set to #stream-items-id, which is the ID of the div that contains the tweets on a Twitter page. This tells the scraper to wait until this element is loaded before scraping the page.
2. Realtime Mode and Callback Mode. GeoNode Scraper API provides two modes for scraping: Realtime Mode and Callback Mode. In Realtime Mode, the API returns the result immediately after the scraping is done. In Callback Mode, the API sends the result to a specified callback URL once the scraping is completed. You can choose the mode that best fits your needs.
3. Check the Status of Your Task. You can check the status of your scraping task using the request ID that you received in the initial response. This allows you to track the progress of your task and determine its completion status.
4. Actions. The Geonode Scraper API allows you to interact with the target document through a list of supported actions. For example, you can use actions to click on a button or fill in a form on the page before scraping.
Analyzing Twitter Data
Once you've scraped and stored Twitter data, the next step is to analyze it. Here's a step-by-step guide:
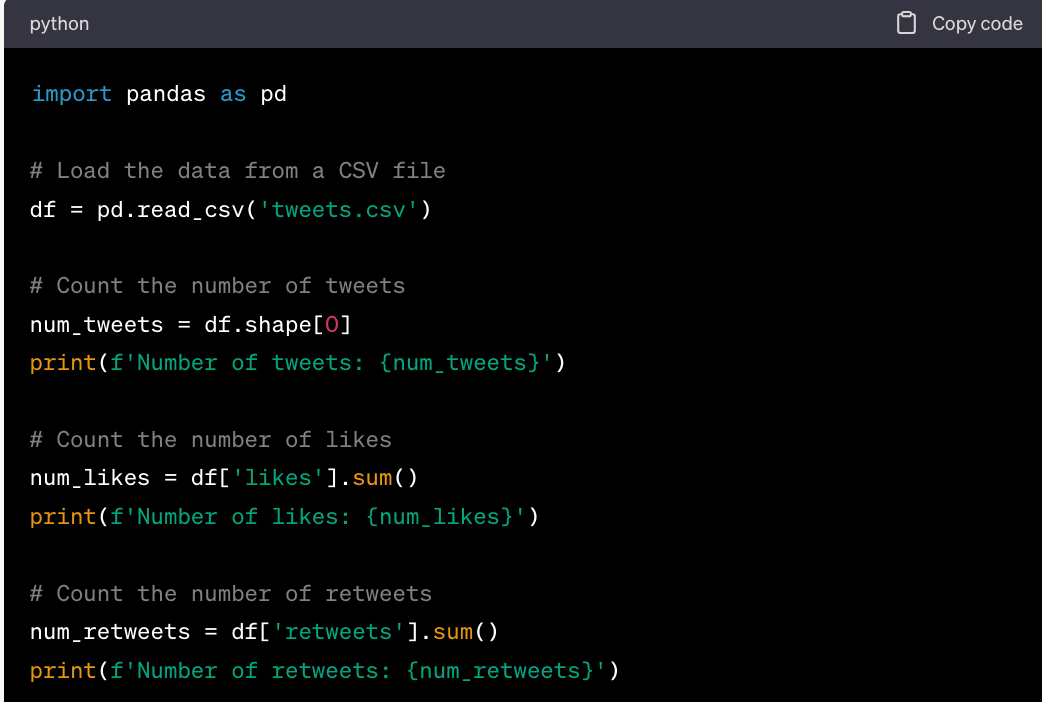
**1. Basic Analysis. **
Basic analysis involves counting tweets, likes, retweets, and other simple metrics. Here's an example of how to do it using pandas, a powerful data analysis library for Python:
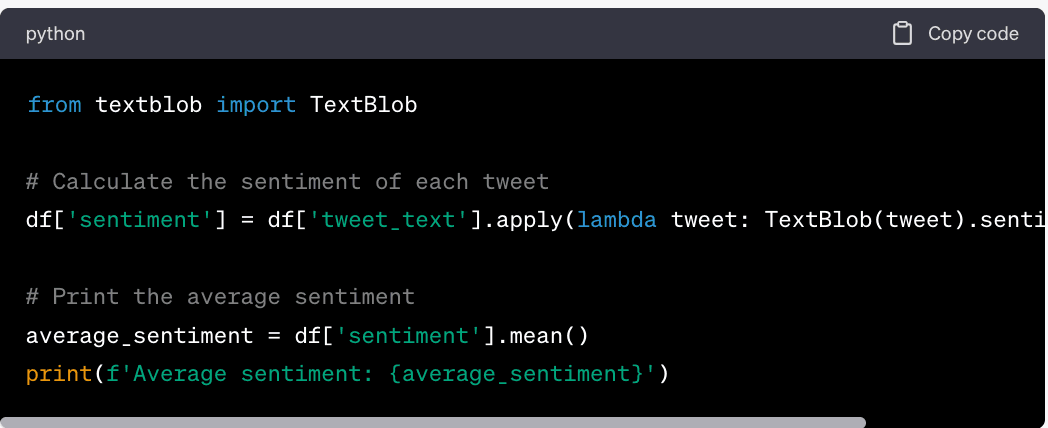
2. Sentiment Analysis
Sentiment analysis involves determining the sentiment of a piece of text, such as a tweet. Here's an example of how to do it using TextBlob, a library for processing textual data:
3. Network Analysis
Network analysis involves analyzing the connections between Twitter users. This can be done using NetworkX, a Python library for the creation, manipulation, and study of the structure, dynamics, and functions of complex networks.
4. Visualizing Twitter Data
Visualizing Twitter data can help you understand it better. This can be done using Matplotlib, a plotting library for Python:

In this code, we first calculate the length of each tweet. We then plot a histogram of tweet lengths, which shows the distribution of tweet lengths.
Remember to replace 'tweets.csv' with the path to your CSV file, and 'tweet_text', 'likes', and 'retweets' with the actual column names in your DataFrame. Also, replace 'user' and 'mentions' with the actual column names for the user and mentions in your DataFrame.
Wrapping Up
In this comprehensive guide, we explored the importance and methods of scraping Twitter data. Twitter, being a vast repository of public opinion, trends, and links, offers a wealth of data that can be harnessed for various purposes, from market research and sentiment analysis to trend forecasting and more.
We've delved into three primary methods of extracting this data:
-
Twitter's API. This is the official way provided by Twitter to interact with its data. It's a powerful tool but comes with its own limitations, such as rate limits and the need for approval of a developer account. However, it's a reliable and straightforward way to access Twitter data, especially when used with libraries like Tweepy.
-
Web Scraping with Python. This method involves using Python libraries like BeautifulSoup and requests to scrape Twitter's website directly. While this method can bypass some of the limitations of Twitter's API, it's more technically involved and can be more fragile due to potential changes in Twitter's website structure.
-
GeoNode's Pay-As-You-Go Scraper. This is a third-party service that provides a more flexible and powerful way to scrape data from Twitter. It offers advanced features like JavaScript rendering and geotargeting, but it comes with its own costs and requires careful usage to avoid unexpected charges.
Each of these methods has its own pros and cons, and the best one to use depends on your specific needs, technical ability, and budget.
As we conclude, it's crucial to emphasize the importance of ethical and responsible data scraping.
While scraping Twitter data can provide valuable insights, it's essential to respect Twitter's terms of service, the privacy of Twitter users, and any relevant laws. Always use the data you scrape responsibly, and when in doubt, seek legal advice.
By understanding the tools and techniques for scraping Twitter data, you're now equipped to harness the power of Twitter data for your own projects.
