uCoin.net is a renowned online platform that serves as a comprehensive catalog for coin collectors and numismatics enthusiasts.
With a vast database that spans various countries, historical periods, and types of coins, it's a go-to resource for anyone interested in the world of coins.
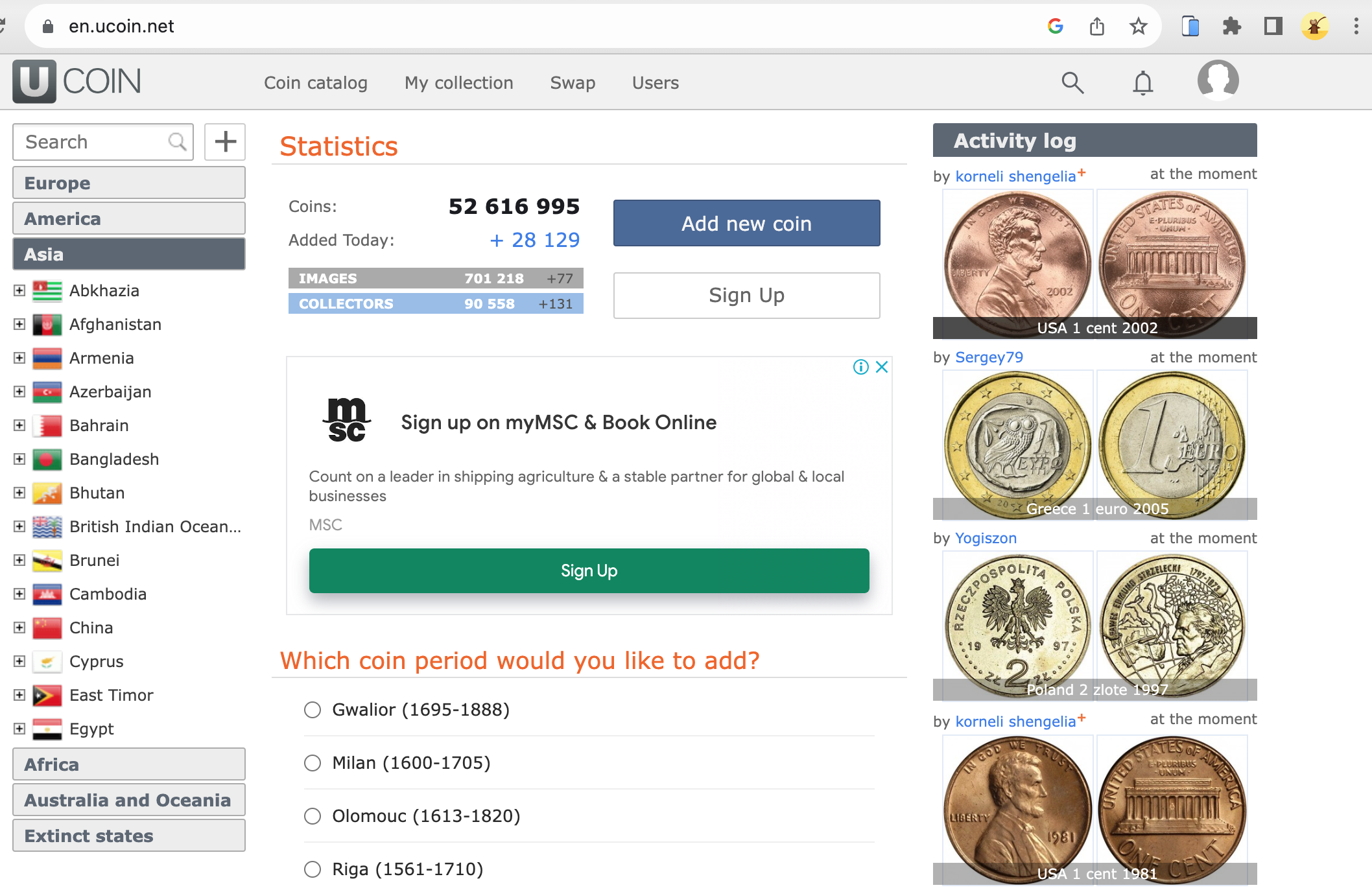
The platform offers features like coin identification, collection management, and even a community for coin swapping.
But while the website is rich in data, accessing this information manually can be time-consuming and inefficient. This is where web scraping comes into play.
Scraping uCoin.net
Knowing the benefits and potential use-cases of scraping data from uCoin.net allows us to understand that clear that the process isn't just a technical exercise; it's a practical approach to unlocking valuable insights and utilities from a treasure trove of numismatic data.
Benefits of Scraping Data from uCoin.net
- Efficiency. Manually collecting data from uCoin.net can be a tedious process, especially for large datasets. Web scraping automates the process and saves time.

- Data Accuracy. Automated scraping minimizes the risk of human error, ensuring that the data collected is accurate and reliable.
- Customization. Scraping allows for tailoring the dataset to specific needs, collecting only the information that is relevant to the project.
- Up-to-Date Information. Web scraping allows for the collection of real-time data, ensuring that your dataset is always current. This is particularly useful for tracking any updates or new additions to the uCoin.net catalog.
- Bulk Data Collection. For those interested in analyzing trends or patterns, scraping provides the ability to collect data in bulk, offering a more comprehensive view of the market or historical trends.
Use Cases of Scraping uCoin.net
- Academic Research. Scholars in the field of numismatics can use scraped data for in-depth studies, such as analyzing the historical significance of certain coins.

- Personal Collection Management. Coin collectors can scrape data to manage their personal collections more effectively. For example, they can keep track of coins they own, coins they wish to acquire, and even the current market value of their collection.
- Market Analysis. Investors and collectors can use the scraped data to analyze market trends, helping them make informed decisions about buying or selling coins.
- Data Journalism. Journalists can use the data to create compelling stories or reports that provide insights into the world of coin collecting, such as the most sought-after coins or notable historical finds.
- App Development. Developers can use the scraped data to create applications or tools that serve the numismatics community, such as price comparison tools, auction platforms, or virtual galleries.
Case Studies and Examples
Academic Research Using uCoin.net Data
uCoin.net is a huge repository of of data for academic researchers interested in numismatics, history, and economics.
The platform's extensive catalog of coins from various countries and time periods provides a rich dataset for scholarly investigation.

Historical Economics. Researchers have utilized uCoin.net data to study the economic conditions of different civilizations based on their coinage. By analyzing the materials used, denominations, and inscriptions, scholars can gain insights into inflation rates, trade relations, and economic stability.
Cultural Studies. The artistic elements of coins, such as designs, symbols, and inscriptions, are also a subject of academic interest. Researchers have scraped uCoin.net to compile datasets that help in understanding the cultural and political messages conveyed through coinage.
Authentication and Counterfeit Detection. Advanced studies have used machine learning algorithms trained on uCoin.net data to distinguish between authentic and counterfeit coins. The high-quality images and detailed descriptions on the platform make it an ideal source for such research.
Data Science in Numismatics. Some academic projects have focused on predictive modeling to estimate the future value of coins. By scraping historical price data from uCoin.net, researchers have been able to apply time-series analysis to forecast trends.
Kaggle Tasks Related to Coin Images
Kaggle, the data science competition platform, has also seen tasks that leverage coin images, some of which could be sourced from uCoin.net or similar platforms.
- Coin Classification. One of the popular Kaggle tasks involves classifying coins based on their images. Participants are provided with a dataset of coin images and are tasked with building a model that can accurately identify the coin's country of origin, denomination, and other attributes.
- Image Segmentation. Another interesting task is image segmentation, where the challenge is to isolate the coin from the background in a given image. This is particularly useful in automated systems that need to identify and count coins.
- Feature Extraction. Advanced Kaggle tasks may require participants to extract specific features from coin images, such as inscriptions or symbols. These features can then be used for various machine learning applications, including clustering and anomaly detection.
- Coin Valuation. Some Kaggle competitions focus on predicting the value of a coin based on its attributes, which can be extracted through image analysis. These tasks often require a combination of computer vision and machine learning techniques.
By examining these case studies and Kaggle tasks, we can see the diverse applications of scraping uCoin.net.
Whether you're an academic researcher, a data scientist, or a hobbyist, the data available on uCoin.net offers a wealth of opportunities for exploration and analysis.
Understanding uCoin.net's Structure
Navigating uCoin.net can be a bit overwhelming for newcomers due to the sheer volume of information available. The website is primarily divided into several main sections:
- Search Bar. Located at the top left side of the page, the search bar allows you to look for specific coins based on various attributes like denomination, year, or country.
- Coin Catalog. This is the heart of uCoin.net, where you'll find detailed listings of coins from around the world. Each listing typically includes images, historical context, and technical specifications like weight, diameter, and composition.

- My Collection. A personalized space where registered users can manage their own coin collections, keep track of swaps, and even wish-list coins they aim to acquire.
- Activity Log. A feature that allows users to track their interactions on the platform, such as coins added to their collection, swaps initiated, and other user engagement metrics. This can be particularly useful for keeping an eye on a user's activity trends over time.
- Swap. This community-driven feature serves as a marketplace for users interested in swapping coins with other collectors.
- Users. A section where profiles of uCoin.net users can be found. It is useful for networking and swapping.
- FAQ. This section provides answers to commonly asked questions about the platform, coin identification, and other related topics.
- News. This is where updates about new additions to the coin catalog or other significant changes to the website are posted.
Understanding the layout is crucial for effective web scraping, as it helps one pinpoint exactly where the necessary data is located.
Types of Data Available on uCoin.net
uCoin.net offers a wealth of data, each serving different needs and interests. Here are some types of data one can expect to find:
- Coin Specifications. Details such as weight, diameter, and material composition.
- Historical Context. Information about the period and country of origin for each coin.
- Images. High-quality images of coins, often featuring both sides.
- Market Value. While uCoin.net is not a trading platform, it sometimes provides approximate market values or links to auction sites for price references.

- User Data. Information about coin swaps, user collections, and wish lists (Note: scraping personal user data without consent may be against uCoin.net's terms of service).
- Geographical Data. Information on the geographical distribution of coins, often categorized by continent and country.
Insights from uCoin.net's FAQ
The FAQ section on uCoin.net provides valuable insights that can guide scraping projects:
Data Limitations. uCoin.net is not a trading platform but a catalog for personal collection management. While users may find market value estimates in the site, these are not to be taken as trading advice.
Coin Identification. The platform offers tools and tips for identifying coins, which could be useful if the scraping project involves automating coin identification.
User Contributions. Only site administrators can add new historical periods or countries to the catalog. This implies that the data is curated, which speaks to its reliability.
Legal and Ethical Considerations

uCoin.net's Terms of Service
Before diving into the technical aspects of scraping uCoin.net, you must familiarize yourself with the platform's Terms of Service (ToS).
While the website serves as a public catalog for coin enthusiasts, it's essential to remember that the data hosted on the platform is governed by specific legal terms.
These terms often outline what you can and cannot do with the data available on the website.
For instance, uCoin.net's ToS may specify restrictions on the use of automated tools for data collection.
Violating these terms could lead to your IP address being banned or even legal repercussions.
Therefore, it's advisable to read through the ToS carefully and, if possible, seek legal advice to ensure that all scraping activities are compliant with the law.
Ethical Guidelines for Web Scraping

Even if web scraping is technically feasible and not explicitly prohibited by uCoin.net's ToS, ethical considerations should guide your actions. Here are some ethical guidelines to follow:
- Rate Limiting. Sending too many requests in a short period can overload the server and affect the website's performance for other users. Implement rate limiting in your scraping code to mimic human behavior.
- User Data Privacy. If your scraping activities involve collecting data that could be considered personal, such as user profiles or swap histories, ensure you have explicit permission to use this data. Scraping personal data without consent is not only unethical but may also be illegal in many jurisdictions.
- Data Integrity. Ensure that your scraping activities do not alter the data on the website in any way. Your aim should be to collect data for analysis, not to modify or delete existing information.
- Transparency. If your project is for academic or research purposes, clearly state your intentions and how the data will be used. Transparency is key to ethical data collection.
- Cite Your Sources. If you plan to publish the data or any derived insights, always give proper credit to uCoin.net as the source of the original data.
- Respect Robots.txt. uCoin.net has a `robots.txt` file that outlines which parts of the site can be scraped and which cannot. Make sure to read and adhere to these guidelines before starting your scraping project.
- Legal Jurisdiction. Laws regarding web scraping can vary by country. Be aware of the laws in your jurisdiction and the jurisdiction where uCoin.net's servers are located.
By adhering to both the legal terms set forth by uCoin.net and following ethical guidelines, you can ensure that your web scraping project is both compliant and respectful of the platform and its users.
This approach not only minimizes risks but also sets a standard for responsible data collection.
Tools and Technologies for uCoin.net Scraping
Python is a popular language for web scraping due to its ease of use and extensive libraries designed to simplify the data extraction process.

Here are some Python libraries commonly used for web scraping:
- Beautiful Soup. Great for parsing HTML and XML documents. It creates a parse tree that can be used to extract data easily.
- Scrapy. More than just a library, Scrapy is an open-source web crawling framework for Python. It's used to extract the data from the website and can also be used to extract data using APIs.
- Selenium. While not strictly a web scraping library, Selenium is often used when the target website relies heavily on JavaScript for rendering content. It automates browser interaction, allowing you to scrape data that's loaded dynamically.
- Requests. This library is used for making various types of HTTP requests. It works well for websites that load their data upfront in the HTML.
- Pandas. Though not a web scraping library, Pandas is often used in tandem with other libraries to clean and organize the scraped data into a format that's easy to analyze.
Other Scraping Tools
OpenNumismat is a handy software for managing your coin collection but can also be adapted for web scraping tasks.

It allows you to create a database of your coin collection, and its architecture can be modified to scrape data from websites like uCoin.net.
While not as flexible as Python libraries, OpenNumismat offers a more user-friendly interface for those who may not be as comfortable with coding.
Investigating Transactions in Cryptocurrencies: Relevance to Scraping
You might wonder what cryptocurrencies have to do with scraping a coin collection website like uCoin.net.
The connection lies in the data analysis techniques used in both fields. When investigating transactions in cryptocurrencies, data scraping is often employed to gather large sets of transaction data for analysis.

The methods used to scrape and analyze cryptocurrency data can be adapted for scraping uCoin.net, especially if you're interested in the economic aspects of coin collecting, such as market trends and valuation.
For instance, you could scrape historical data on coin valuations from uCoin.net and use analytical techniques common in cryptocurrency research to predict future trends in the numismatic market.
By understanding and utilizing the right tools and technologies, you can make your web scraping project more efficient, ethical, and insightful. Whether you're a seasoned coder or a hobbyist, there's a tool out there that can meet your web scraping needs.
Step-by-Step Guide to Scraping uCoin.net
Setting Up Your Environment
Before you start scraping, it's essential to set up a conducive environment that supports the tools and libraries you'll be using. Here's how to go about it:
- Install Python. If you haven't already, download and install Python from the official website. Make sure to install pip, Python's package installer, as well.
- Virtual Environment. It's a good practice to create a virtual environment for your scraping project. This isolates your project and its dependencies from other Python projects you may have. Use the following commands to set it up:

- Install Libraries. Once inside your virtual environment, install the necessary Python libraries like Beautiful Soup, Scrapy, and Requests.

Pro Tip:
- Use a text editor like Visual Studio Code, Sublime Text, or any IDE you're comfortable with for writing your code.
- Familiarize yourself with the Developer Tools in your web browser. This will help you inspect the HTML elements you wish to scrape.
Writing the Scraping Code
Now that your environment is set up, you can start writing the code to scrape uCoin.net. Below is a simplified example using Python and Beautiful Soup:
- Import Libraries

- Make a Request

- Parse HTML

- Find Elements

- Extract Data

Note: This is a simplified example. Your actual code will depend on the specific data you wish to scrape from uCoin.net.
Data Storage Options
After scraping the data, you'll need a place to store it. Here are some options:
- CSV File. Python's `csv` library can be used to write the scraped data into a CSV file. This is a good option for smaller datasets.
- Database. For larger datasets, consider using a database like MySQL or MongoDB. Python has libraries like `PyMySQL` and `PyMongo` to interact with these databases.
- JSON File. If your data is hierarchical or nested, storing it in a JSON file might be more appropriate. Python's `json` library can help with this.

- Cloud Storage. Services like AWS S3 or Google Cloud Storage can be used for even larger datasets, especially if you plan to integrate the data into a larger pipeline or analytics system.
By following this step-by-step guide, you'll be well on your way to scraping uCoin.net efficiently and ethically. Remember to always refer back to the legal and ethical considerations to ensure your scraping is compliant with all regulations.
Troubleshooting and FAQs
Common Issues and Their Solutions
When scraping uCoin.net, you may encounter various challenges. Here are some common issues and their respective solutions:
-
IP Address Blocked. If you send too many requests in a short period, uCoin.net might block your IP address.
Solution: Implement rate limiting in your code to mimic human behavior and avoid sending rapid consecutive requests.
Alternatively, you can use Geonode rotating proxies to change your IP address periodically, making it less likely for you to get blocked.
-
Incomplete Data. Sometimes, you might find that the data you've scraped is incomplete or missing some elements.
Solution: This usually happens when the website uses JavaScript to load content dynamically.
In such cases, consider using a library like Selenium to interact with the JavaScript elements. Geonode rotating proxies can also be useful here to refresh the session and capture dynamic content.
-
Encoding Issues. Special characters in coin names or descriptions may not appear correctly.
Solution: Make sure to set the correct character encoding when parsing the HTML.
For example, in Python's `requests` library, you can specify the encoding like so: `response.encoding = 'utf-8'`.
-
Session Timeouts. If you're scraping data that requires you to be logged in, you might experience session timeouts.
Solution: Use session objects in your code to persist login sessions across multiple requests.
Geonode rotating proxies can help maintain session integrity by providing a stable connection.
-
Legal Concerns. You may be unsure if your scraping activities are compliant with uCoin.net's Terms of Service.
Solution: Always refer to the website's ToS and consult legal advice if necessary.
People Also Ask

How Can I Add New Historical Periods to uCoin.net?
To add a new historical period to uCoin.net, you can start by reaching out to the site administrators through the 'Contact Us' section. Prepare a detailed dataset about the coins from the missing period, including images, denominations, and materials. After submission, the data undergoes a community validation process for accuracy and completeness. Once approved, the new historical period and its associated coins are added to uCoin.net's database for public access.
Can I Use uCoin.net for Trading?
uCoin.net is not just a coin catalog; it also supports trading between users. The site features a 'Swap' section for listing tradeable coins and allows users to gauge trustworthiness through user ratings. Private messaging is available for discussing trade terms. While the platform helps initiate trades, the actual transactions occur off-platform, and users are advised to exercise caution during the process.By addressing these commonly asked questions, this article aims to provide a comprehensive guide to scraping uCoin.net, covering everything from the technical aspects to practical use-cases and community features.
How Can I Identify Coins Using uCoin.net?
uCoin.net provides various tools for coin identification, including a basic search bar for key attributes and an advanced search for more detailed queries. If these methods fail, users can seek help from the community by posting in the 'Users' or 'Swap' sections. The platform's FAQ section also offers additional guidance on effective coin identification.
Wrapping Up
uCoin.net is a valuable resource for coin collectors, researchers, and data scientists alike.
In this article, we covered the technical aspects of scraping the platform, including setting up your environment, choosing the right tools and technologies, and writing the scraping code.
We also looked into the ethical and legal considerations to ensure your scraping activities are both responsible and compliant.
As you embark on your web scraping journey, you may find other resources helpful for deepening your knowledge and honing your scraping skills, such as
Web Scraping with Python and BeautifulSoup
Scrapy Documentation
Geonode Scraper API
Numisia uCoin.net Forum
By following this guide and exploring additional resources, you'll be well-equipped to undertake your own web scraping projects, whether you're interested in coin collecting, academic research, or data science.
